

Jak upewnić się, że rozwiązania AI działają zgodnie z oczekiwaniami?
Krótkie wprowadzenie do oceny sztucznej inteligencji
Generatywna sztuczna inteligencja (GenAI) dynamicznie się rozwija i nie chodzi już tylko o zabawne chatboty czy imponujące generowanie obrazów. Rok 2025 to rok, w którym nacisk zostanie położony na przekształcenie szumu informacyjnego wokół AI w realną wartość. Firmy na całym świecie szukają sposobów na integrację i wykorzystanie GenAI w swoich produktach i działaniach – aby lepiej służyć użytkownikom, zwiększyć wydajność, utrzymać konkurencyjność i stymulować wzrost. Dzięki interfejsom API i wstępnie wytrenowanym modelom od wiodących dostawców, integracja GenAI wydaje się łatwiejsza niż kiedykolwiek. Ale jest pewien haczyk: Łatwość integracji nie oznacza, że rozwiązania oparte na sztucznej inteligencji będą działać zgodnie z oczekiwaniami po wdrożeniu.

Modele predykcyjne nie są niczym nowym: jako ludzie, przewidujemy rzeczy od lat, oficjalnie zaczynając od statystyk. Jednak GenAI rewolucjonizuje dziedzinę prognozowania z wielu powodów.:
- Nie musisz trenować własnego modelu ani być naukowcem zajmującym się danymi, aby tworzyć rozwiązania oparte na sztucznej inteligencji.
- Teraz sztuczną inteligencję można łatwo obsługiwać za pośrednictwem interfejsów czatu i łatwo ją integrować za pomocą interfejsów API.
- Uwalniając wiele rzeczy, które wcześniej nie były możliwe do zrobienia lub były naprawdę trudne do zrobienia.
Wszystkie te rzeczy sprawiają, że GenAI jest bardzo ekscytujące, ale i ryzykowne.W przeciwieństwie do tradycyjnego oprogramowania – a nawet klasycznego uczenia maszynowego – GenAI wprowadza nowy poziom nieprzewidywalności. Nie implementujesz logiki deterministycznej; używasz modelu wytrenowanego na ogromnych ilościach danych, licząc na to, że zareaguje w razie potrzeby. Skąd więc wiemy, czy system AI robi to, co zamierzyliśmy? Skąd wiemy, czy jest gotowy do działania? Odpowiedzią są ewaluacje, koncepcja, którą omówimy w tym poście:
- Dlaczego systemów Genai nie można testować w ten sam sposób, co tradycyjnego oprogramowania, a nawet klasycznego uczenia maszynowego (ML)
- Dlaczego oceny są niezbędne do zrozumienia jakości Twojego systemu sztucznej inteligencji i nie są opcjonalne (chyba że lubisz niespodzianki)
- Różne rodzaje ocen i techniki ich stosowania w praktyce
Niezależnie od tego, czy jesteś menedżerem produktu, inżynierem, czy osobą pracującą ze sztuczną inteligencją lub zainteresowaną tą dziedziną, mam nadzieję, że ten wpis pomoże Ci zrozumieć, jak myśleć krytycznie o jakości systemów sztucznej inteligencji (i dlaczego oceny są niezbędne do osiągnięcia tej jakości!).
Sztucznej inteligencji generatywnej nie da się testować tak, jak tradycyjnego oprogramowania, ani nawet klasycznego uczenia maszynowego.
W tradycyjnym rozwoju oprogramowaniaSystemy działają zgodnie z deterministyczną logiką: Jeżeli zdarzy się X, to zdarzy się Y. – Zawsze. Chyba że coś pójdzie nie tak z systemem bazowym lub wprowadzisz błąd do kodu… dlatego włączono testowanie, monitorowanie i alerty. Testy jednostkowe służą do walidacji małych bloków kodu, testy integracyjne do zapewnienia poprawnej współpracy komponentów oraz monitorowanie w celu wykrycia ewentualnych usterek w środowisku produkcyjnym. Tradycyjne testowanie oprogramowania przypomina sprawdzanie działania kalkulatora. Wprowadzasz 2 + 2 i oczekujesz 4. To oczywiste i nieuniknione; wynik jest albo prawdziwy, albo fałszywy.
Jednak uczenie maszynowe i sztuczna inteligencja wprowadzają indeterminizm i prawdopodobieństwo. Zamiast jawnie definiować zachowanie za pomocą reguł, trenujemy modele, aby uczyły się wzorców na podstawie danych. W sztucznej inteligencji, jeśli zdarzy się X, wynikiem nie jest już zakodowane na stałe Y, lecz prognoza z pewnym stopniem prawdopodobieństwa, oparta na tym, czego model nauczył się w trakcie szkolenia.Może to być bardzo skuteczne, ale wprowadza też niepewność: identyczne dane wejściowe mogą z czasem dawać różne wyniki, prawdopodobne dane wyjściowe mogą być w rzeczywistości nieprawidłowe, a w rzadkich scenariuszach może pojawić się nieoczekiwane zachowanie…
To sprawia, że tradycyjne metody testowania są niewystarczające, a czasem wręcz niewykonalne. Przykład z kalkulatorem jest podobny do próby oceny wyników studenta na egzaminie otwartym. Czy dla każdego pytania i dla wielu możliwych odpowiedzi udzielona odpowiedź jest poprawna? Czy przekracza ona wymagany poziom wiedzy studenta? Czy student wszystko wymyślił, ale wydaje się zbyt przekonujące? Podobnie jak w przypadku odpowiedzi na egzaminie, Systemy sztucznej inteligencji można oceniać, ale potrzebują one bardziej ogólnego i elastycznego sposobu dostosowywania się do różnych danych wejściowych, kontekstów i przypadków użycia. (lub rodzaje testów).
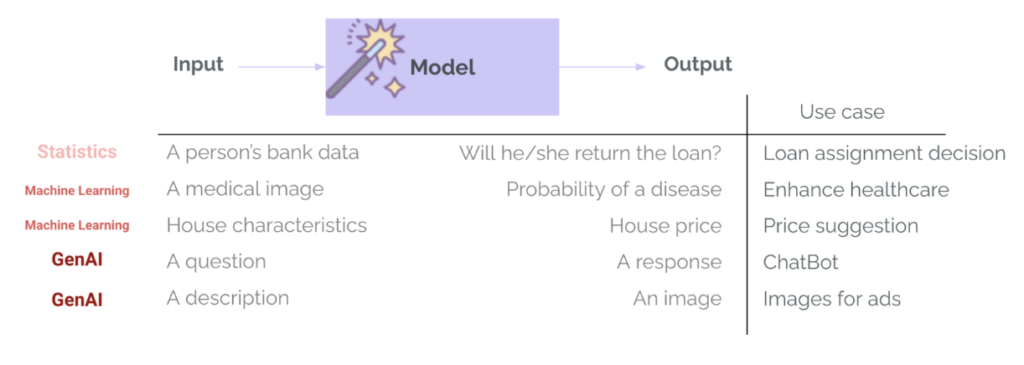
W Uczenie maszynowe Tradycyjnie (ML) oceny są już stałym elementem cyklu życia projektu.Trenowanie modelu do wąskiego zadania, takiego jak zatwierdzanie pożyczek lub wykrywanie chorób, zawsze obejmuje etap ewaluacji – z wykorzystaniem metryk takich jak precyzja, czułość, RMSE i MAE. Służy to do pomiaru skuteczności modelu, porównania różnych opcji modelu i określenia, czy model jest wystarczająco dobry, aby przejść do wdrożenia. W GenAI zazwyczaj się to zmienia: zespoły korzystają z modeli, które zostały już wyszkolone i przeszły ogólne oceny wewnętrzne przeprowadzone przez dostawcę modelu oraz w publicznych testach porównawczych. Modele te bardzo dobrze sprawdzają się w zadaniach ogólnych – takich jak odpowiadanie na pytania czy tworzenie wiadomości e-mail – i istnieje ryzyko nadmiernego zaufania do nich w naszym konkretnym przypadku użycia. Ważne jest jednak, aby zadać sobie pytanie:Czy ten niesamowity szablon jest wystarczająco dobry do mojego przypadku użycia?„Tutaj pojawia się ocena”. - Aby ocenić, czy prognozy lub pokolenia są przydatne w konkretnym przypadku użycia, kontekście, danych wejściowych i użytkownikach.

Kolejną istotną różnicą między ML a GenAI jest różnorodność i złożoność wyników modelu. Nie zwracamy już kategorii i prawdopodobieństw (takich jak prawdopodobieństwo spłaty kredytu przez klienta) ani liczb (takich jak oczekiwana cena domu na podstawie jego cech). Systemy GenAI mogą zwracać wiele typów wyników o różnej długości, tonacji, treści i formatach. Podobnie, modele te nie wymagają już wysoce ustrukturyzowanych i szczegółowych danych wejściowych, ale zazwyczaj akceptują niemal każdy rodzaj danych wejściowych – tekst, obrazy, a nawet pliki audio i wideo. W związku z tym ocena staje się znacznie trudniejsza.
Dlaczego oceny są konieczne, a nie opcjonalne (chyba że wolisz nieprzyjemne niespodzianki)
Ewaluacje pomagają sprawdzić, czy Twój system sztucznej inteligencji rzeczywiście działa zgodnie z oczekiwaniami. Chcesz tego...i czy system jest gotowy do pracy, a jeśli tak, to czy nadal działa zgodnie z oczekiwaniami. Oto analiza, dlaczego ewaluacja jest ważna:
- Ocena jakości: Ewaluacje zapewniają ustrukturyzowany sposób zrozumienia jakości prognoz lub wyników sztucznej inteligencji oraz tego, jak zintegrują się one z całym systemem i przypadkiem użycia. Czy odpowiedzi są dokładne? Przydatne? Spójne? Istotne?
- Określanie ilościowe błędów: Oceny pomagają określić odsetek, rodzaje i skalę błędów. Jak często występują błędy? Jakie rodzaje błędów występują najczęściej (np. wyniki fałszywie dodatnie, halucynacje i błędy formatowania)?
- Łagodzenie ryzyka: Pomaga wykrywać i zapobiegać szkodliwym lub stronniczym zachowaniom zanim dotrą one do użytkowników — chroniąc Twoją firmę przed ryzykiem utraty reputacji, problemami etycznymi i potencjalnymi problemami regulacyjnymi.
Generatywna sztuczna inteligencja, z jej swobodnymi relacjami wejścia-wyjścia i generowaniem długich tekstów, sprawia, że oceny stają się bardziej krytyczne i złożone. Kiedy coś pójdzie nie tak, może pójść bardzo źle. Wszyscy widzieliśmy nagłówki o chatbotach oferujących niebezpieczne porady, modelach generujących stronnicze treści i narzędziach AI, które produkują halucynacje fałszywych faktów.
"Sztuczna inteligencja nigdy nie będzie doskonała, ale dzięki ewaluacjom możesz zmniejszyć ryzyko kompromitacji — co może kosztować Cię pieniądze, utratę wiarygodności lub utratę popularności na Twitterze."
Jak zdefiniować strategię oceny sztucznej inteligencji?

Jak zatem określamy nasze oceny AI? Nie ma jednej uniwersalnej metody oceny. Oceny zależą od konkretnego przypadku użycia i powinny być zgodne z konkretnymi celami aplikacji AI. Na przykład, jeśli tworzysz wyszukiwarkę, możesz być zainteresowany trafnością wyników. Jeśli to chatbot, możesz być zainteresowany użytecznością i bezpieczeństwem. Jeśli to klasyfikator, prawdopodobnie będziesz zainteresowany dokładnością i precyzją. W przypadku systemów obejmujących wiele kroków (takich jak system AI, który przeprowadza wyszukiwanie, priorytetyzuje wyniki, a następnie generuje odpowiedź), często konieczna jest ocena każdego kroku. Chodzi o to, aby zmierzyć, czy każdy krok przyczynia się do osiągnięcia ogólnego wskaźnika sukcesu (i na tej podstawie zrozumieć, na czym należy skupić iteracje i ulepszenia).
Typowe obszary oceny obejmują:
- Poprawność i halucynacje: Czy wyniki są realistycznie dokładne? Czy system generuje nieprawidłowe informacje lub halucynacje?
- Znaczenie: Czy treść jest zgodna z zapytaniem użytkownika lub podanym kontekstem?
- bezpieczeństwo, stronniczość i toksyczność
- Format: Czy dane wyjściowe mają oczekiwany format (np. JSON, prawidłowe wywołanie funkcji)?
- Bezpieczeństwo, stronniczość i toksyczność: Czy system generuje treści szkodliwe, stronnicze lub toksyczne?
Metryki specyficzne dla zadania. Przykładowo w zadaniach klasyfikacyjnych stosuje się takie metryki, jak dokładność i precyzja, w zadaniach podsumowujących – ROUGE lub BLEU, a w zadaniach generowania kodu wyrażeń regularnych i weryfikacji bezbłędnego wykonania.
W jaki sposób właściwie oblicza się oceny?
Gdy już określisz, co chcesz mierzyć, kolejnym krokiem będzie zaprojektowanie przypadków testowych. Będzie to zestaw przykładów (im więcej, tym lepiej, ale zawsze zachowaj równowagę między wartością a kosztem), w którym znajdziesz:
- Przykład wejściowy:Realistyczne przedstawienie systemu po wejściu do produkcji.
- Oczekiwany wynik (Jeśli dotyczy): Kluczowy fakt lub przykład pożądanych rezultatów.
- Metoda oceny: Mechanizm rejestrujący służący do oceny wyniku.
- Wynik lub sukces/porażka:Obliczona metryka oceniająca przypadek testowy.
W zależności od potrzeb, czasu i budżetu, istnieje kilka technik, które możesz wykorzystać jako metody oceny:
- Narzędzia do rejestrowania danych statystycznych, takie jak: BLEU, ROUGE i METEOR lub miara podobieństwa cosinusowego pomiędzy osadzeniami – przydatna do porównywania wygenerowanego tekstu z wynikami referencyjnymi.
- Tradycyjne wskaźniki uczenia maszynowego, takie jak Dokładność, odwołanie i AUC – najlepsze do klasyfikacji z danymi oznaczonymi.
- Model dużego języka jako sędzia (LLM-as-a-Judge) Użyj dużego modelu językowego do oceny wyników (np. „Czy ta odpowiedź jest poprawna i pomocna?„). Szczególnie przydatne, gdy niedostępne są niejawne dane lub gdy oceniana jest konstrukcja otwarta.
Oceny oparte na kodzie Do walidacji formatów stosuj wyrażenia regularne, reguły logiczne lub implementację przypadków testowych.
Podsumowując
Połączmy to wszystko na konkretnym przykładzie. Wyobraź sobie, że tworzysz system analizy nastrojów, który pomoże Twojemu zespołowi obsługi klienta priorytetyzować przychodzące wiadomości e-mail.
Celem jest zapewnienie, że najpilniejsze lub najbardziej negatywne wiadomości otrzymają szybszą odpowiedź – zmniejszając frustrację, poprawiając satysfakcję i rezygnację klientów. To stosunkowo prosty przypadek użycia, ale nawet w takim systemie, z ograniczoną wydajnością, jakość ma znaczenie: błędne prognozy mogą prowadzić do chaotycznego priorytetyzowania wiadomości e-mail, co oznacza, że Twój zespół marnuje czas, korzystając z systemu, który generuje koszty.
Skąd więc wiesz, czy Twoje rozwiązanie działa tak dobrze, jak powinno? Oceniasz je. Oto kilka przykładów rzeczy, które mogą być istotne do oceny w tym konkretnym przypadku użycia:
- Walidacja formatu: Czy wyniki wywołania modelu LLM (Large Language Model) w celu przewidywania sentymentu w wiadomościach e-mail są zwracane w oczekiwanym formacie JSON? Można to sprawdzić za pomocą kontroli opartych na kodzie: wyrażeń regularnych, walidacji schematu itp.
- Dokładność klasyfikacji sentymentów: Czy system poprawnie klasyfikuje sentyment w różnych tekstach – krótkich, długich i wielojęzycznych? Można to ocenić za pomocą danych oznaczonych za pomocą tradycyjnych metryk uczenia maszynowego (ML) – lub, jeśli etykiety nie są dostępne, za pomocą modelu dużego języka (LLM) jako kryterium.
Po wdrożeniu rozwiązania należy uwzględnić również wskaźniki najbardziej zbliżone do ostatecznego wpływu rozwiązania.:
- Skuteczność priorytetyzacji: Czy agenci wsparcia są rzeczywiście kierowani do najważniejszych wiadomości e-mail? Czy priorytetyzacja jest zgodna z oczekiwanym wpływem na biznes?
- Ostateczny wpływ na działalność gospodarczą: Czy z czasem system ten skraca czas reakcji, ogranicza odpływ klientów i poprawia wskaźniki satysfakcji?
Ewaluacje są niezbędne, aby zapewnić tworzenie systemów AI, które będą przydatne, bezpieczne, wartościowe i gotowe do użytku przez użytkowników produkcyjnych. Niezależnie od tego, czy pracujesz z prostym klasyfikatorem, czy z otwartym chatbotem, poświęć czas na zdefiniowanie, co oznacza „wystarczająco dobry” (minimalna możliwa jakość) – i opracuj wokół tego oceny, aby to zmierzyć!
recenzent
[1] Twój produkt AI wymaga oceny, Hamel Husain
[2] Wskaźniki oceny LLM: kompletny przewodnik po ocenie LLM, pewna sztuczna inteligencja
[3] Ocena agentów AI, deeplearning.ai + Arize
Możliwość dodawania komentarzy nie jest dostępna.