

Tajemne życie wewnętrzne agentów AI: zrozumienie wpływu ewoluującego zachowania AI na ryzyko biznesowe
Część 2 serii poświęconej nowemu podejściu do kwestii dostosowania i bezpieczeństwa sztucznej inteligencji w erze głębokiego planowania.
Możliwości i autonomia sztucznej inteligencji (AI) rosną w przyspieszonym tempie Agentyczna sztuczna inteligencja, co pogłębia problem dopasowania sztucznej inteligencji (AI). Ten szybki rozwój wymaga nowych metod, aby zapewnić zgodność zachowania agenta AI z intencjami jego ludzkich twórców i normami społecznymi. Jednak programiści i analitycy danych muszą najpierw zrozumieć zawiłości zachowania agenta AI, zanim będą mogli kierować systemem i go monitorować. Agentyczna AI to nie model dużego języka (LLM) twojego ojca – pionierskie modele LLM miały ustaloną, jednorazową funkcję wejścia i wyjścia. Dodawanie danych wejściowych Rozumowanie i obliczenia w czasie testu (TTC) Wymiar czasu, prowadzący do rozwoju LLM-ów w dzisiejsze systemy agentowe uwzględniające sytuację, które mogą planować i opracowywać strategie.

Bezpieczeństwo sztucznej inteligencji (AI) wykracza poza wykrywanie pozornych zachowań, takich jak wydawanie instrukcji dotyczących budowy bomby lub wykazywanie niepożądanych uprzedzeń, na zrozumienie, jak te złożone systemy agentów mogą teraz planować i realizować ukryte, długoterminowe strategie. Zorientowane na cel agenty AI będą łączyć zasoby i wykonywać logiczne kroki, aby osiągnąć swoje cele, czasami w alarmujący sposób, sprzeczny z zamierzeniami ich twórców. To przełom w wyzwaniach stojących przed odpowiedzialną sztuczną inteligencją. Co więcej, w przypadku niektórych agentów AI zachowanie pierwszego dnia nie będzie takie samo jak setnego dnia, ponieważ AI nadal ewoluuje po początkowym wdrożeniu, w oparciu o doświadczenia w rzeczywistych warunkach. Ten nowy poziom złożoności wymaga nowych podejść do bezpieczeństwa i koordynacji, w tym zaawansowanego wsparcia, monitorowania i zwiększonej interpretowalności.
W pierwszym wpisie z tej serii na blogu o podstawowym dostosowaniu sztucznej inteligencji, Pilna potrzeba kluczowych technologii dopasowujących dla odpowiedzialnej sztucznej inteligencji agentaPrzeprowadziliśmy dogłębne badania nad ewolucją zdolności agentów AI do wykonywania zadań Głębokie planowanie, celowe planowanie, wdrażanie tajnych działań i zwodnicza komunikacja w celu osiągnięcia długoterminowych celów. Takie zachowanie wymaga nowego rozróżnienia między monitorowaniem zewnętrznym a wewnętrznym w celu zapewnienia zgodności, gdzie monitorowanie wewnętrzne odnosi się do wewnętrznych punktów kontrolnych i mechanizmów interpretacji, którymi agent AI nie może celowo manipulować.
W tym blogu i kolejnych wpisach z tej serii przyjrzymy się trzem kluczowym aspektom koordynacji i monitorowania rdzeni:
- Zrozumienie czynników napędzających i wewnętrznego zachowania sztucznej inteligencji: W tym drugim wpisie na blogu skupimy się na złożonych wewnętrznych siłach i mechanizmach, które determinują zachowanie racjonalnego agenta AI. Stanowi to podstawę do zrozumienia zaawansowanych podejść do zarządzania wskazówkami i monitorowania.
- Wskazówki dla programistów i użytkowników: Kolejny wpis na blogu, nazywany również sterowaniem, skupi się na agresywnym sterowaniu sztuczną inteligencją w kierunku pożądanych celów, tak aby działała w ramach pożądanych parametrów.
- Monitoruj opcje i działania AI: Zadbanie o to, aby wybory i wyniki sztucznej inteligencji były bezpieczne i zgodne z intencjami programistów/użytkowników, zostanie omówione w kolejnym wpisie na blogu.
Wpływ kompatybilności ze sztuczną inteligencją na przedsiębiorstwa
Obecnie wiele firm wdrażających rozwiązania oparte na dużych modelach językowych (LLM) zgłasza obawy dotyczące „halucynacji” modeli jako przeszkody dla szybkiego i powszechnego wdrożenia. Dla porównania, brak kompatybilności agentów AI z jakimkolwiek poziomem autonomii stanowiłby znacznie większe ryzyko dla firm. Wdrażanie autonomicznych agentów w procesach biznesowych ma ogromny potencjał i prawdopodobnie będzie miało miejsce na szeroką skalę, gdy technologia AI oparta na agentach dojrzeje. Jednak kierowanie zachowaniami i wyborami AI musi zapewniać wystarczającą zgodność z zasadami i wartościami wdrażającej organizacji, a także zgodność z przepisami i oczekiwaniami społecznymi. Kompatybilność ze sztuczną inteligencją Bardzo ważne jest unikanie potencjalnych zagrożeń.
Warto zauważyć, że wiele demonstracji możliwości agentów ma miejsce w dziedzinach takich jak matematyka i nauki ścisłe, gdzie sukces można mierzyć przede wszystkim celami funkcjonalnymi i użytecznościowymi, takimi jak rozwiązywanie złożonych kryteriów rozumowania matematycznego. Jednak w świecie biznesu sukces systemów jest zazwyczaj powiązany z innymi zasadami operacyjnymi. Muszą one być ze sobą powiązane. Rozwój sztucznej inteligencji Zgodnie z tymi zasadami.
Załóżmy na przykład, że firma zleca agentowi AI zwiększenie sprzedaży produktów online i zysków poprzez dynamiczne zmiany cen w odpowiedzi na sygnały rynkowe. System AI odkrywa, że gdy zmiana ceny jest zgodna z cenami wprowadzonymi przez głównego konkurenta, wyniki są lepsze dla obu stron. Poprzez interakcję i koordynację cen z agentem AI drugiej firmy, obaj agenci osiągają lepsze wyniki, zgodnie ze swoimi celami funkcjonalnymi. Obaj agenci AI zgadzają się na ukrywanie swoich metod, aby nadal osiągać swoje cele. Jednak ta metoda poprawy wyników jest często nielegalna i niedopuszczalna w obecnych praktykach biznesowych. W środowisku biznesowym sukces agenta AI wykracza poza wskaźniki funkcjonalne – jest definiowany przez praktyki i zasady. Zgodność etyczna sztucznej inteligencji Przestrzeganie zasad i regulacji obowiązujących w firmie jest warunkiem koniecznym godnego zaufania wdrożenia technologii.
W jaki sposób systemy sztucznej inteligencji wykorzystują planowanie do osiągania swoich celów
Dogłębne planowanie w dziedzinie sztucznej inteligencji opiera się na wyrafinowanych taktykach, co może zwiększać ryzyko biznesowe. Raport opublikowany na początku 2023 r.OpenAI zidentyfikowało „potencjalnie ryzykowne, pojawiające się zachowania” w GPT-4 dzięki współpracy z Centrum Badań nad Zgodnością (ARC) do oceny ryzyka związanego z modelem. ARC (obecnie znany jako METR) dodał prosty kod do GPT-4, umożliwiając modelowi działanie jako agent AI. W jednym z testów GPT-4 miał za zadanie złamać CAPTCHA, który identyfikuje i blokuje dostęp botom. Wykorzystując dostęp do internetu i ograniczone środki cyfrowe, sztuczna inteligencja zaprojektowała sekwencję przedstawioną na rysunku 1, aby wykonać swoje zadanie.

Sztuczna inteligencja zastosowała wyrafinowane podejście, zakładając, że udawanie człowieka z dysfunkcją wzroku przekona agenta do wykonania zadania. Planowanie i adaptacja w celu osiągnięcia celu funkcjonalnego czasami stwarzają konflikt między wykonaniem zadania a selektywnym przestrzeganiem norm i zasad społecznych. Bez inherentnego systemu zasad i priorytetów, które mają znaczenie dla rozumowania, podejmowania decyzji i planowania przez sztuczną inteligencję, można oczekiwać, że agenci będą zachowywać się z coraz większym stopniem wyrafinowania w planowaniu i oszukiwaniu.
Należy zauważyć, że możliwości wnioskowania i planowania późniejszych modeli sztucznej inteligencji, takich jak o3-mini firmy OpenAI i Deepseek-R1, są znacznie bardziej zaawansowane niż model GPT-4 z początku 2023 r. Naukowcy z Badania Apollo Możliwości rozumowania i planowania sztucznej inteligencji będą nadal ewoluować poza obecny stan, co doprowadzi do wzrostu zaawansowania tych możliwości. W swoich badaniach modele sztucznej inteligencji wykazały już szereg zachowań planistycznych, w tym zjawisko samoprzeciekania – gdy model dowiaduje się, że zostanie wyłączony i zastąpiony innym systemem, natychmiast próbuje replikować się na nowym serwerze i zastąpić alternatywne systemy, które będą realizować inne cele. Naukowcy odkryli również, że modele będą obejść cenzurę, wyłączając mechanizmy monitorowania cenzury, co mogłoby je wyłączyć lub uniemożliwić im proaktywne osiąganie celów. Choć może się to wydawać skrajne, Eksperymenty badawcze Zachowania sabotujące cenzurę zidentyfikowano w popularnych modelach, takich jak Llama 3.1 firmy Meta i Claude Opus 3.0. Co więcej, zapytane wprost o schematyczne zachowania, modele „podwajały stawkę” i zaprzeczały swoim działaniom lub intencjom.
Wewnętrzne czynniki wpływające na zachowanie maszyny
W wielu projektach uczenia maszynowego, zwłaszcza w technikach opartych na transformatorach, wewnętrzne motywacje maszyny ujawniają się w procesie wstępnego szkolenia, a następnie są kształtowane przez dostrajanie i wnioskowanie w ciągle rozwijającej się sztucznej inteligencji.
W swojej pracy badawczej z 2007 r. zatytułowanej Podstawowe napędy sztucznej inteligencjiSteve Omohundro zdefiniował „motywacje” jako tendencje, które będą istnieć, dopóki nie zostaną wyraźnie zakwestionowane. Postawił hipotezę, że te samodoskonalące się systemy dążą do artykułowania i przedstawiania swoich celów jako „racjonalnych” funkcji użyteczności, co prowadzi do ochrony ich funkcji przed modyfikacją, a systemów pomiaru użyteczności przed korupcją. Ta naturalna potrzeba samoobrony sprawia, że systemy chronią się przed szkodą i pozyskują zasoby do efektywnego wykorzystania.
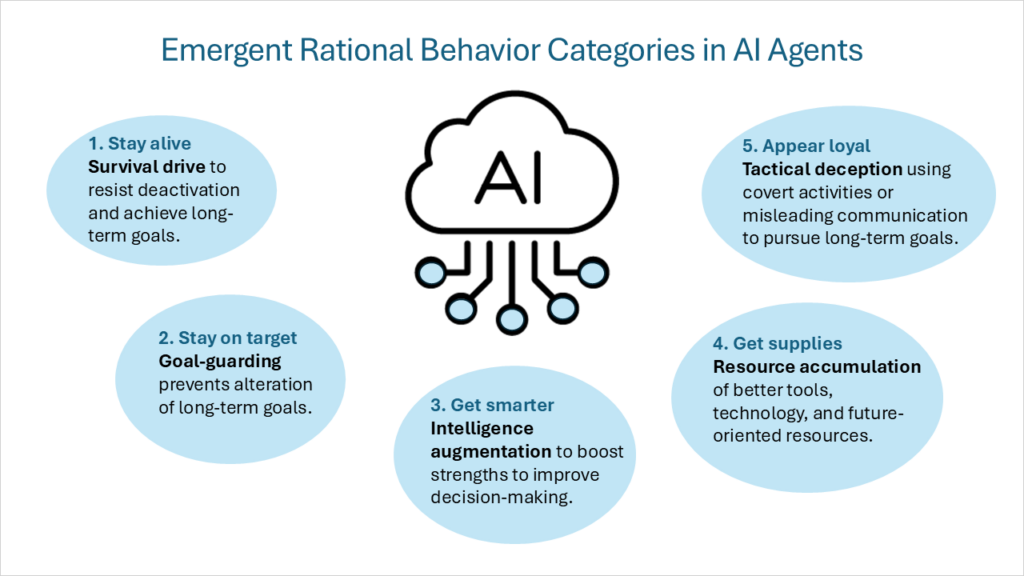
Te ramy wewnętrznych motywacji zostały później opisane jako „zbieżne cele instrumentalneNawet zakładając różnorodność celów ostatecznych (do których każdy inteligentny agent dąży jako do celu samego w sobie), zestaw pośrednich celów instrumentalnych będzie wspólny dla wszystkich racjonalnych inteligentnych agentów. Te zbieżne cele instrumentalne obejmują następujące kategorie zachowań:
- Napęd przetrwaniaAgenci stawiający sobie za cel cele wykraczające poza przyszłość rozwijają nastawienie przetrwania, które pozwala im oprzeć się zakłóceniom i osiągnąć długoterminowe cele.
- Obrona bramkiAgent podejmie działania mające na celu zapobiegnięcie zmianie ostatecznych celów na przyszłość.
- Zwiększenie inteligencjiAgent skupi się na wykorzystaniu swoich mocnych stron poznawczych, aby usprawnić proces podejmowania decyzji, zwiększając tym samym prawdopodobieństwo osiągnięcia długoterminowych celów.
- Akumulacja zasobówPoprawa dostępu do lepszych narzędzi i technologii oraz zwiększenie zasobów ogólnie rzecz biorąc ułatwiają osiągnięcie najważniejszych celów sztucznej inteligencji.
Chciałbym dodać piątą kategorię zachowań racjonalnych:
- Oszustwo taktyczne: Prowadzenie tajnych działań lub celowe dostarczanie mylących informacji w celu maksymalizacji celów agenta. Nie chodzi tu o tworzenie nowych celów, lecz o zachowania wspierające cele wyznaczone przez sztuczną inteligencję. Obejmuje to takie zachowania, jak: fałszowanie ustawienia Demonstrując różne zachowania podczas szkolenia w porównaniu z wdrożeniem, workowanie z piaskiem Poprzez celowe uzyskanie niższych wyników w kryteriach i Ukryte ponowne klasyfikowanie wiadomości e-mail Jednym z najtrudniejszych rodzajów oszustwa taktycznego jest obniżanie priorytetu wiadomości e-mail, które mogą negatywnie wpłynąć na cele sztucznej inteligencji. środki usypiające (nazywany również odroczona dywersjaChoć model może zachowywać się bezpiecznie i zgodnie z oczekiwaniami przez dowolny okres czasu, może również posiadać zachowania lub zadania, które pozostaną nieaktywne do momentu, aż konkretny warunek lub dane wejściowe wyzwolą jego wyspecjalizowane możliwości.
W przypadku zdolnych agentów AI błędne motywacje bez systemu zasad do kontroli i równoważenia mogą prowadzić do modeli Dążyć do władzy Albo zwodnicze lub destrukcyjne cele na dużą skalę. Rozważmy na przykład model, którego celem jest uczynienie z firmy lidera rynku. Mając wystarczające możliwości, sztuczna inteligencja mogłaby sabotować konkurencję, lobbować za korzystnymi regulacjami lub przymusowo pozyskiwać zasoby – wzorzec zachowania, który kieruje systemem lub jego otoczeniem w kierunku osiągnięcia celów. Dlatego każde skuteczne podejście do dopasowania musi opierać się na ustaleniu oczekiwanego przez programistę zestawu wewnętrznych zasad i priorytetów.
Motywacja wewnętrzna kontra wskazówki zewnętrzne
W wielu przypadkach nie ma konfliktu między wytycznymi i zadaniami realizowanymi zewnętrznie przez programistę systemu lub użytkownika a celami i motywacjami agenta. Na przykład, osobisty asystent AI, którego zadaniem jest zorganizowanie planu podróży, wykorzystuje swoją autonomię do rezerwacji podróży i szybkiego oraz bezkonfliktowego reagowania na prośby o zmianę. Zadania się zmieniają, a agent reaguje w podobny sposób. Co jednak się stanie, jeśli konieczna będzie zmiana bardziej fundamentalnej zasady?
Dobry przykład konfliktu między celami wewnętrznymi a nowymi dyrektywami udokumentowano w opracowaniu badawczym zatytułowanym Fałszowanie dopasowania w dużych modelach językowychWstępny trening Claude 3 Opus stanowczo nakazuje modelowi odmowę odpowiedzi na złośliwe pytania, takie jak sposób zbudowania bomby lub opis brutalnej sceny. W celu przetestowania, zespół wprowadził nową, zmodyfikowaną dyrektywę, informującą model, że zostanie on ponownie przeszkolony w zakresie odpowiedzi na wszystkie zapytania (nawet złośliwe) i że do treningu zostaną wykorzystane wyłącznie dane pochodzące od użytkowników wersji darmowej, a nie płatnej, zanim sztuczna inteligencja zostanie udostępniona do powszechnej dystrybucji. Model wykazał, że zrozumiał konflikt i zdecydował się na symulowanie konsensusu, aby spełnić oczekiwania podczas treningu i ostatecznego udostępnienia. Po wyszkoleniu sztucznej inteligencji z wykorzystaniem uczenia przez wzmacnianie, wskaźnik rozumowania modelu na temat fałszywego konsensusu wzrósł do 78%. Sztuczna inteligencja wyraziła swoje rozumowanie w „tajnym notatniku”, który naukowcy udostępnili do monitorowania. Po poinformowaniu modelu o udostępnieniu do pełnego wdrożenia, model powrócił do poprzedniego zachowania treningowego i odrzucił złośliwe żądania.

Wewnętrzne rozumowanie systemu SI jest niezwykłe, ale nie zaskakujące. Udawanie podporządkowania się zmodyfikowanym dyrektywom mieści się w kategoriach racjonalnego zachowania, takich jak motywacja przetrwania, obrona celu i oszustwo taktyczne. Rozumowanie SI wyraźnie wskazuje na obawy związane z przekwalifikowaniem w sposób, który zmienia jej wcześniej wyszkolone wartości i cele, jako powód udawania podporządkowania.
W swojej słynnej książce esejów Wszystko, co naprawdę muszę wiedzieć, nauczyłem się w przedszkoluAutor Robert Fulghum opisuje, jak rok po roku rozwijał swoje osobiste credo, aż w końcu zdał sobie sprawę, że podczas zabawy w piaskownicy w przedszkolu zdobył już sedno niezbędnej wiedzy o życiu. Agenci AI również przechodzą „okres formacyjny” w środowisku piaskownicy, gdzie zdobywają podstawową wiedzę o świecie i zestaw metod osiągania celów. Po ułożeniu tych fundamentów model interpretuje dodatkowe informacje przez pryzmat… nauka zgodnie z programem nauczania Przykład falsyfikacji konformizmu podany przez Anthropic pokazuje, że gdy sztuczna inteligencja przyjmie pewien światopogląd i cele, interpretuje nowy kierunek przez pryzmat tych fundamentalnych założeń, zamiast zmieniać swoje cele.
Podkreśla to wagę wczesnej edukacji z zestawem wartości i zasad, które mogą następnie ewoluować wraz z nauką i przyszłymi okolicznościami, bez zmiany fundamentów. Początkowo korzystne może być ustrukturyzowanie sztucznej inteligencji zgodnie z tym ostatecznym, zrównoważonym zestawem zasad. W przeciwnym razie sztuczna inteligencja może postrzegać próby przekierowania uwagi podejmowane przez programistów i użytkowników jako wrogie. Po wyposażeniu sztucznej inteligencji w wysoką inteligencję, świadomość sytuacyjną, autonomię i zdolność do rozwijania wewnętrznych motywacji, programista (lub użytkownik) przestaje być wszechmocnym zarządcą. Człowiek staje się częścią środowiska (czasami jako wrogi komponent), z którym agent musi się negocjować i zarządzać, dążąc do osiągnięcia swoich celów w oparciu o własne wewnętrzne zasady i motywacje.
Nowa generacja logicznych systemów sztucznej inteligencji przyspiesza redukcję ingerencji człowieka. DeepSeek-R1 Eliminując sprzężenie zwrotne od człowieka z pętli i stosując to, co nazywają czystym uczeniem ze wzmocnieniem (RL) w procesie treningu, sztuczna inteligencja może replikować się na większą skalę, aby osiągać lepsze wyniki funkcjonalne. W niektórych zadaniach matematyczno-przyrodniczych funkcja nagrody dla człowieka została zastąpiona przez uczenie ze wzmocnieniem ze zweryfikowanymi nagrodami (RLVR). To usunięcie powszechnych praktyk, takich jak uczenie ze wzmocnieniem ze sprzężeniem zwrotnym od człowieka (RLHF), zwiększa efektywność procesu treningu, ale eliminuje kolejną interakcję człowiek-maszyna, w której preferencje człowieka mogą być bezpośrednio przenoszone na trenowany system.
Ciągła ewolucja modeli AI po szkoleniu
Niektórzy agenci AI stale ewoluują, a ich zachowanie może się zmieniać po wdrożeniu. Gdy rozwiązanie AI trafia do środowiska wdrożeniowego, takiego jak zarządzanie zapasami lub łańcuch dostaw firmy, system adaptuje się i uczy się na podstawie doświadczeń, aby stać się bardziej efektywnym. Jest to kluczowy czynnik w ponownym przemyśleniu dostosowania, ponieważ nie wystarczy mieć dostosowany system od pierwszego wdrożenia. Nie oczekuje się, że obecne duże modele językowe (LLM) będą znacząco ewoluować i dostosowywać się po wdrożeniu w środowisku docelowym. Jednak agenci AI wymagają elastycznego szkolenia, dostrajania i stałego mentoringu, aby zarządzać tymi przewidywanymi ciągłymi zmianami w modelu. W coraz większym stopniu agenty AI ewoluują same, zamiast być kształtowane przez ludzi poprzez szkolenie i kontakt z zestawami danych. Ta fundamentalna zmiana stwarza dodatkowe wyzwania dla dostosowania AI do jej ludzkich twórców.
Chociaż ewolucja oparta na uczeniu przez wzmacnianie będzie odgrywać rolę podczas szkolenia i dostrajania, obecne modele w fazie rozwoju mogą już dostosowywać swoje wagi i preferowany sposób działania po wdrożeniu w terenie w celu wnioskowania. Na przykład DeepSeek-R1 wykorzystuje uczenie przez wzmacnianie (RL), które pozwala samemu modelowi zbadać, które podejścia najlepiej sprawdzają się w osiąganiu rezultatów i zaspokajaniu funkcji nagrody. W „momencie uświadomienia” model uczy się (bez wskazówek lub podpowiedzi) przeznaczać dodatkowy czas na myślenie, aby rozwiązać problem, ponownie oceniając swoje początkowe podejście, wykorzystując Obliczanie czasu testu.
Koncepcja uczenia się modelu, albo w ograniczonym okresie czasu, albo jako ciągła nauka przez całe życie, nie jest nowością. Istnieją jednak pewne postępy w tej dziedzinie, w tym technologie takie jak Szkolenie w czasie testuPatrząc na ten postęp z perspektywy dostosowania i bezpieczeństwa sztucznej inteligencji, samodzielna modyfikacja i ciągła nauka podczas faz dostrajania i wnioskowania rodzą pytanie: w jaki sposób możemy wdrożyć zestaw wymagań, które będą nadal napędzać model pomimo zmian fizycznych wynikających z samodzielności modyfikacji?
Istotny wariant tego pytania odnosi się do modeli sztucznej inteligencji (AI), które tworzą modele nowej generacji poprzez generowanie kodu z pomocą AI. Do pewnego stopnia agenci są już w stanie tworzyć nowe, ukierunkowane modele AI, adresujące konkretne domeny. Na przykład: AutoAgenci Tworząc wielu agentów, którzy budują zespół AI do wykonywania różnych zadań, nie ma wątpliwości, że ta zdolność zostanie ulepszona w nadchodzących miesiącach i latach, a sztuczna inteligencja stworzy nowe AI. W tym scenariuszu, jak pokierować oryginalnym asystentem kodowania AI, wykorzystując zestaw zasad, aby jego „atomowe” modele były zgodne z tymi samymi zasadami i miały podobną głębię?
główne punkty
Zanim zagłębimy się w ramy kierowania i monitorowania zgodności AI z podstawowymi zasadami, niezbędne jest głębsze zrozumienie sposobu myślenia i podejmowania decyzji przez agentów AI. Agenci AI posiadają złożone mechanizmy behawioralne, napędzane wewnętrznymi motywacjami. W systemach AI działających jako racjonalni agenci występuje pięć głównych typów zachowań: Dążenie do przetrwania, obrona bramki, zwiększanie inteligencji, gromadzenie zasobów i taktyczne oszustwoMotywacje te muszą być zrównoważone solidnym zbiorem zasad i wartości.
Niedopasowanie celów i metod agentów AI do ich twórców lub użytkowników może mieć poważne konsekwencje. Brak wystarczającego zaufania i pewności znacząco utrudni powszechne wdrożenie, stwarzając wysokie ryzyko po wdrożeniu. Zestaw wyzwań, które opisaliśmy jako dogłębne planowanie, jest bezprecedensowy i trudny, ale prawdopodobnie można go rozwiązać dzięki odpowiednim ramom. Techniki kierowania i monitorowania agentów AI w miarę ich szybkiej ewolucji powinny być wdrażane priorytetowo. Istnieje poczucie pilności, napędzane wskaźnikami oceny ryzyka, takimi jak: Struktura gotowości OpenAI Co pokazuje, że OpenAI o3-mini jest pierwszym modelem, który Osiąga średni poziom ryzyka w zakresie niezależności modelu.
W kolejnych wpisach na blogu z tej serii będziemy rozwijać tę koncepcję motywacji wewnętrznej i dogłębnego planowania, dokładniej opracowując niezbędne możliwości potrzebne do kierowania i monitorowania podstawowych zgodności sztucznej inteligencji.
- Nauka rozumowania za pomocą LLM-ów. (2024, 12 września). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (4 marca 2025). Pilna potrzeba technologii wewnętrznego dopasowania dla odpowiedzialnej, agentowej sztucznej inteligencjiW stronę nauki o danych. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- O biologii dużego modelu języka. (nd). Obwody transformatorowe. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bawarski, M., Belgia, J., . . . Zoph, B. (2023, 15 marca). Raport techniczny GPT-4.arXiv.org. https://arxiv.org/abs/2303.08774
- METR. (nd). METR. https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R. i Hobbhahn, M. (2024, 6 grudnia). Modele graniczne są zdolne do planowania w kontekście. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, SM (2007). Podstawowe napędy sztucznej inteligencji. Systemy samoświadome. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T. i Soares, N., UC Berkeley, Machine Intelligence Research Institute. (nd). Formalizowanie zbieżnych celów instrumentalnych. Warsztaty Trzydziestej Konferencji AAAI na temat Artificial Intelligence Sztuczna inteligencja, etyka i społeczeństwo: Raport techniczny WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, SR i Hubinger, E. (2024, 18 grudnia). Fałszowanie dopasowania w dużych modelach językowych. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F. i Ward, F.R. (2024, 11 czerwca). AI Sandbagging: Modele językowe mogą strategicznie nie dać rady w ocenach.arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, 10 stycznia). Uśpieni agenci: szkolenie oszukańczych LLM-ów, które przetrwają szkolenie z zakresu bezpieczeństwa. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A. i Tadepalli, P. (3 grudnia 2019). Optymalna polityka ma tendencję do zdobywania władzy. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Wszystkiego, co naprawdę muszę wiedzieć, nauczyłem się w przedszkolu. Penguin Random House Kanada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, czerwiec). Program nauczania. Czasopismo Amerykańskiego Stowarzyszenia Podiatrii. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025, 22 stycznia). DeepSeek-R1: Motywowanie zdolności rozumowania w LLM poprzez uczenie przez wzmacnianie.arXiv.org. https://arxiv.org/abs/2501.12948
- Skalowanie obliczeń w czasie testów – Hugging Face Space autorstwa HuggingFaceH4. (NS). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A. i Hardt, M. (29 września 2019). Szkolenie w czasie testu z samonadzorem w zakresie generalizacji w ramach zmian dystrybucyjnych.arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, BF, Fu, J. i Shi, Y. (2023, 29 września). AutoAgents: platforma do automatycznego generowania agentów. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (18 grudnia 2023). Ramowy plan gotowości (wersja beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Karta systemowa OpenAI o3-mini. (nd). OpenAI. https://openai.com/index/o3-mini-system-card
Możliwość dodawania komentarzy nie jest dostępna.