

Meta uczy modele sztucznej inteligencji sztuki odróżniania ważnych poleceń od innych.
Modele logiczne, takie jak OpenAI o1 i DeepSeek-R1, mają problem z nadmiernym myśleniem. Jeśli zada się im proste pytanie, takie jak „Ile jest 1+1?”, zastanowią się przez kilka sekund, zanim odpowiedzą.

W idealnym przypadku modele sztucznej inteligencji, podobnie jak ludzie, powinny być w stanie określić, kiedy udzielić bezpośredniej odpowiedzi, a kiedy przeznaczyć dodatkowy czas i zasoby na zastanowienie się przed udzieleniem odpowiedzi. Nowa technologia Zaprezentowane przez badaczy w Meta sztuczna inteligencja وUniwersytet Illinois w Chicago Dzięki szkoleniu modeli w zakresie przydzielania budżetów wnioskowania na podstawie stopnia trudności zapytań, uzyskuje się szybsze odpowiedzi, niższe koszty i lepszą alokację zasobów obliczeniowych.
kosztowne rozumowanie
Duże modele językowe (LLM) mogą poprawić swoją wydajność w zadaniach wnioskowania, generując dłuższe łańcuchy rozumowania, często nazywane „łańcuchami myśli” (CoT). Sukces techniki CoT doprowadził do powstania całego zestawu technik skalowania czasu wnioskowania, które zmuszają model do głębszego „przemyślenia” problemu, wygenerowania i przeanalizowania wielu odpowiedzi oraz wybrania najlepszej.
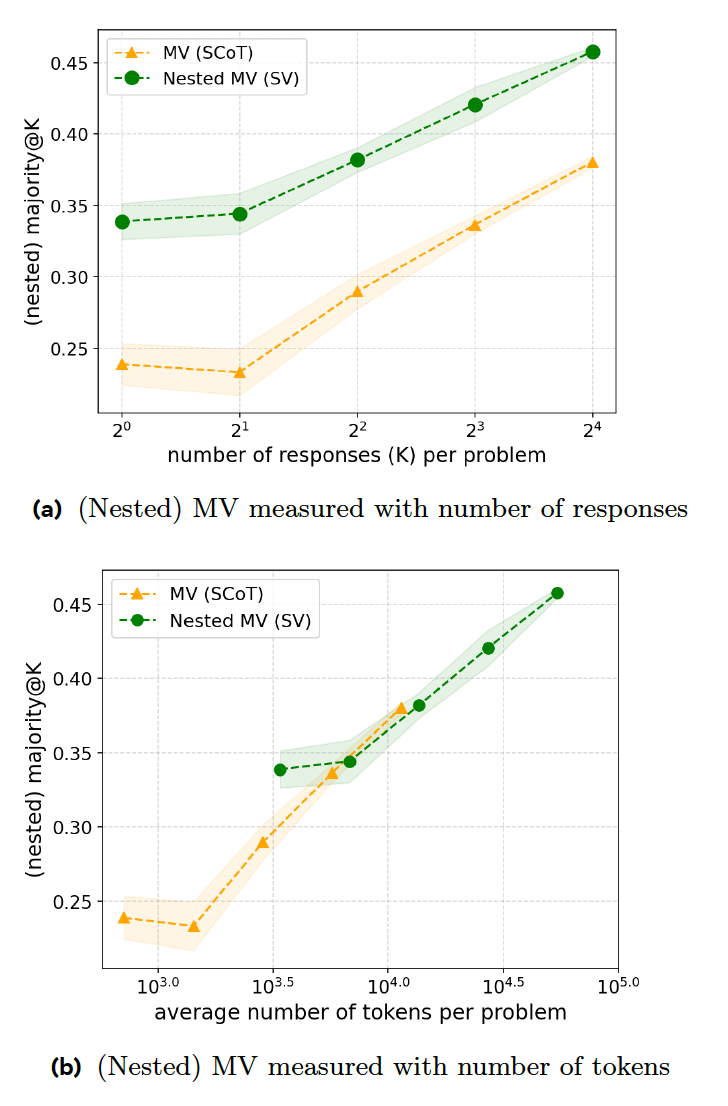
Głosowanie większościowe (MV) to kluczowa metoda stosowana w modelach wnioskowania, w których generowane są liczne odpowiedzi, a następnie wybierana jest najczęściej zadawana odpowiedź. Problem z tym podejściem polega na tym, że model przyjmuje jednorodne zachowanie, traktując każde dane wejściowe jako trudny problem wnioskowania i zużywając niepotrzebne zasoby na generowanie wielu odpowiedzi.
Inteligentne rozumowanie
W nowym artykule badawczym zaproponowano szereg technik szkoleniowych, które zwiększają efektywność modeli wnioskowania w udzielaniu odpowiedzi. Pierwszym krokiem jest „głosowanie sekwencyjne” (SV), w którym model przerywa proces wnioskowania, gdy dana odpowiedź pojawi się określoną liczbę razy. Na przykład, model jest proszony o wygenerowanie maksymalnie ośmiu odpowiedzi i wybranie tej, która pojawi się co najmniej trzy razy. Jeśli model otrzyma proste zapytanie, o którym mowa powyżej, pierwsze trzy odpowiedzi będą prawdopodobnie podobne, co doprowadzi do wcześniejszego przerwania procesu, oszczędzając czas i zasoby obliczeniowe.
Ich eksperymenty pokazują, że SV przewyższa klasyczny MV w zadaniach konkursowych, generując taką samą liczbę odpowiedzi. Jednak SV wymaga dodatkowych instrukcji i generowania kodu, co stawia go na równi z MV pod względem stosunku kodu do dokładności.
Druga technika, Adaptacyjne Głosowanie Sekwencyjne (ASV), usprawnia SV, wymagając od modelu analizy problemu i generowania wielu odpowiedzi tylko wtedy, gdy problem jest trudny. W przypadku prostych problemów (takich jak wniosek 1+1), model po prostu generuje jedną odpowiedź, bez przechodzenia przez proces głosowania. Dzięki temu model jest bardziej wydajny w obsłudze zarówno prostych, jak i złożonych problemów.
Uczenie się przez wzmacnianie
Chociaż zarówno techniki SV, jak i ASV poprawiają wydajność modelu, wymagają one znacznej ilości ręcznie etykietowanych danych. Aby złagodzić ten problem, naukowcy proponują optymalizację polityki wnioskowania z ograniczonym budżetem (IBPO), algorytm uczenia się przez wzmacnianie, który uczy model dostosowywania długości ścieżek wnioskowania w oparciu o trudność zapytania.
IBPO zostało zaprojektowane tak, aby umożliwić dużym modelom językowym (LLM) ulepszanie swoich odpowiedzi przy jednoczesnym zachowaniu ograniczeń budżetu wnioskowania. Algorytm uczenia się przez wzmacnianie pozwala modelowi przekroczyć korzyści uzyskane dzięki trenowaniu na ręcznie oznaczonych danych poprzez ciągłe generowanie trajektorii ASV, ocenę odpowiedzi i wybieranie wyników, które zapewniają poprawną odpowiedź i optymalny budżet wnioskowania.
Ich eksperymenty pokazują, że IBPO poprawia front Pareto, co oznacza, że przy stałym budżecie wnioskowania model wytrenowany na IBPO przewyższa inne modele bazowe.
Odkrycia te pojawiają się w kontekście ostrzeżeń badaczy, że obecne modele sztucznej inteligencji borykają się z problemami. Firmy mają trudności ze znalezieniem wysokiej jakości danych szkoleniowych i poszukują alternatywnych sposobów na ulepszenie swoich modeli.
Obiecującym rozwiązaniem jest uczenie przez wzmacnianie, w którym modelowi wyznacza się cel i umożliwia się znalezienie własnych rozwiązań, w przeciwieństwie do nadzorowanego dostrajania (ang. SFT), w którym model jest trenowany na ręcznie oznaczonych przykładach.
Co zaskakujące, model ten często znajduje rozwiązania, których ludzie nie brali pod uwagę. Wydaje się, że ta formuła sprawdziła się w przypadku DeepSeek-R1, który podważył dominację amerykańskich laboratoriów sztucznej inteligencji.
Naukowcy zauważają, że „metody oparte na poleceniach i SFT mają trudności z absolutną optymalizacją i wydajnością, co potwierdza przypuszczenie, że samo SFT nie zapewnia możliwości samokorygowania. Obserwację tę potwierdzają również prace równoległe, które sugerują, że to samokorygujące zachowanie pojawia się spontanicznie w czasie rzeczywistym, a nie jest generowane ręcznie przez polecenia lub SFT”.
Możliwość dodawania komentarzy nie jest dostępna.