

Osiąganie pewności w dużych modelach językowych (LLM) przy użyciu inteligentnych obwodów decyzyjnych
Niepewność nie jest niczym nowym w technologii – wszystkie nowoczesne systemy radzą sobie z niepewnymi danymi wejściowymi i wyjściowymi, wykorzystując matematycznie sprawdzone struktury sterowania.
Obietnica agentów AI podbiła świat. Agenci mogą wchodzić w interakcje z otaczającym ich światem, pisać artykuły (ale nie ten), podejmować działania w Twoim imieniu i ogólnie rzecz biorąc, ułatwiać i udostępniać najtrudniejszą część automatyzacji dowolnego zadania.
Agenci koncentrują się na najtrudniejszych elementach procesów i szybko rozwiązują problemy. Czasami zbyt szybko – jeśli proces z udziałem agentów wymaga udziału człowieka w podejmowaniu decyzji o wyniku, faza weryfikacji przez człowieka może stać się wąskim gardłem procesu.
Przykładem procesu zależnego od agenta jest przetwarzanie i klasyfikowanie połączeń telefonicznych klientów. Nawet agent z 99.95% dokładnością popełni 5 błędów, odsłuchując 10 000 połączeń. Mimo że o tym wie, agent nie może Ci tego powiedzieć. Który 5 na 10 000 połączeń zostało błędnie sklasyfikowanych.

Technika „LLM-as-a-Judge” to technika, w której każdy sygnał wejściowy jest wprowadzany do innego procesu LLM w celu oceny poprawności danych wyjściowych. Ponieważ jednak jest to inny proces LLM, może on również być niedokładny. Te dwa procesy probabilistyczne tworzą macierz pomyłek z wynikami prawdziwie dodatnimi, fałszywie ujemnymi, prawdziwie ujemnymi i fałszywie dodatnimi.
Innymi słowy, zgłoszenie prawidłowo sklasyfikowane przez proces LLM może zostać uznane za nieprawidłowe przez jego sędziego LLM i odwrotnie.
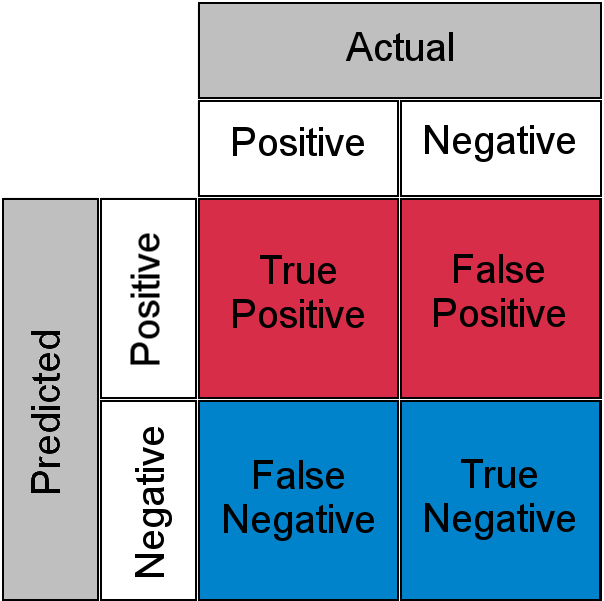
z powodu tego " Nieznane znane „W przypadku wrażliwego obciążenia człowiek musi przejrzeć i zrozumieć wszystkie 10 000 połączeń. Znów wracamy do tego samego problemu wąskiego gardła.
Jak możemy zwiększyć pewność statystyczną naszych procesów sterowanych agentami? W tym poście tworzę system, który pozwala nam zwiększyć pewność w procesach sterowanych agentami, uogólniam go na dowolną liczbę agentów i opracowuję funkcję kosztową, która pomoże nam w planowaniu przyszłych inwestycji w system. Kod, którego używam w tym poście, jest dostępny w moim repozytorium. obwody decyzyjne sztucznej inteligencji.
Obwody decyzyjne AI
Wykrywanie i korekcja błędów to nie są nowe koncepcje. Korekcja błędów ma kluczowe znaczenie w takich dziedzinach jak elektronika cyfrowa i analogowa. Nawet postęp w dziedzinie komputerów kwantowych opiera się na rozszerzaniu możliwości korekcji i detekcji błędów. Możemy czerpać inspirację z tych systemów i wdrażać podobne rozwiązania z agentami sztucznej inteligencji. Na przykład, Algorytmy sztucznej inteligencji Zaawansowane wykorzystanie technik korekcji błędów stosowanych w systemach komunikacyjnych.
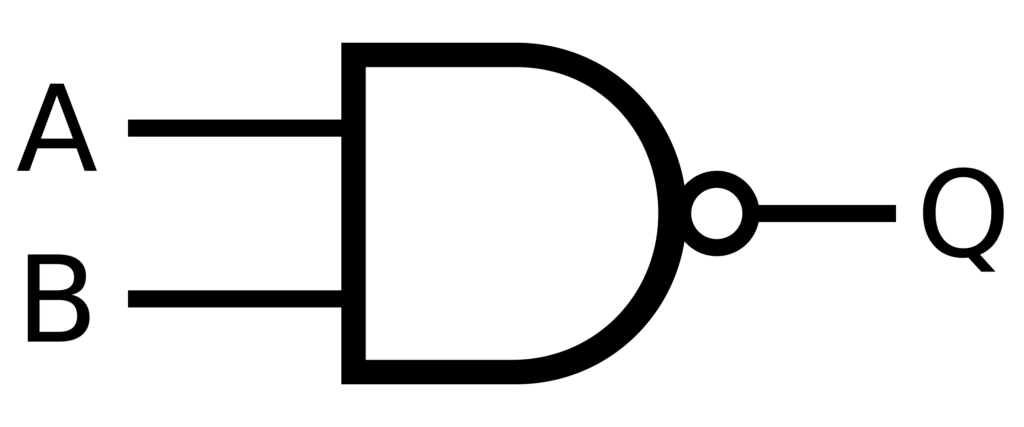
W logice Boole'a bramki NAND są Świętym Graalem obliczeń, ponieważ mogą wykonywać dowolne operacje. Są funkcjonalnie kompletne, co oznacza, że dowolną operację logiczną można utworzyć przy użyciu wyłącznie bramek NAND. Tę zasadę można zastosować w systemach sztucznej inteligencji do tworzenia solidnych struktur decyzyjnych z wbudowaną korekcją błędów. Pozwala to na tworzenie… sieci neuronowe Bardziej niezawodne i zdolne do obsługi niekompletnych lub zaszumionych danych.
Od obwodów elektronicznych do inteligentnych obwodów decyzyjnych (AI)
Tak jak obwody elektroniczne wykorzystują powtarzanie i weryfikację, aby zapewnić niezawodność obliczeń, tak inteligentne układy decyzyjne (AI) mogą wykorzystywać wielu agentów o różnych perspektywach, aby uzyskać dokładniejsze wyniki. Te obwody można budować, wykorzystując zasady teorii informacji i logiki Boole’a:
- Przetwarzanie nadmiarowe: Wielu agentów AI przetwarza te same dane wejściowe niezależnie, podobnie jak współczesne procesory (CPU) wykorzystują redundantne obwody do wykrywania błędów sprzętowych. Ten proces zwiększa niezawodność systemu AI.
- Mechanizmy konsensusu: Wyniki decyzji są łączone za pomocą systemów głosowania lub średnich ważonych, podobnych do większościowych bramek logicznych w elektronice odpornej na błędy. Mechanizmy te gwarantują, że ostateczna decyzja odzwierciedla konsensus agentów.
- Agenci walidujący: Specjalistyczni audytorzy AI sprawdzają racjonalność wyników, działając podobnie do kodów wykrywających błędy, takich jak Bity parzystości أو cykliczne kontrole nadmiarowe (kontrole CRC)Agenci ci redukują prawdopodobieństwo podjęcia błędnych decyzji.
- Integracja z udziałem człowieka: Strategiczna weryfikacja przez człowieka w kluczowych momentach procesu decyzyjnego, podobnie jak systemy biometryczne wykorzystują nadzór ludzki jako ostatnią warstwę weryfikacji. Gwarantuje to, że ważne decyzje podlegają ocenie człowieka.
Matematyczne podstawy obwodów decyzyjnych w sztucznej inteligencji
Niezawodność tych systemów można określić ilościowo, stosując teorię prawdopodobieństwa.
Prawdopodobieństwo awarii wynika po pierwsze z zaobserwowanej dokładności w czasie w zestawie danych testowych przechowywanych w systemie takim jak LangSmitha.

W przypadku współczynnika o dokładności 90% prawdopodobieństwo awarii, p_1، 1–0.9 Jest to 0.1 czyli 10%.

Prawdopodobieństwo, że dwa niezależne czynniki zawiodą przy tym samym wejściu, jest iloczynem prawdopodobieństwa, że oba czynniki okażą się dokładne:
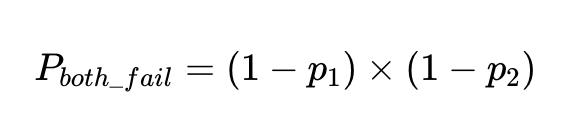
Jeżeli wykonamy N operacji z tymi klientami, całkowita liczba niepowodzeń wynosi
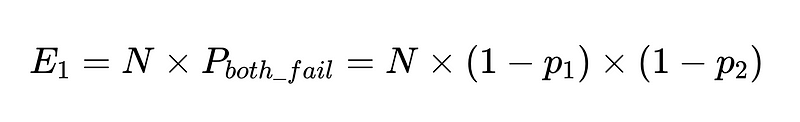
Tak więc w przypadku 10 000 wykonań między dwoma niezależnymi pracownikami z dokładnością 90% oczekiwana liczba niepowodzeń wynosi 100.
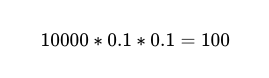
Jednak nadal nie wiemy. Który Spośród tych 10 000 połączeń telefonicznych, 100 zakończyło się porażką.
Możemy połączyć cztery rozszerzenia tej idei, aby zapewnić bardziej niezawodne rozwiązanie, które zapewni pewność co do każdej danej odpowiedzi:
- Podstawowy klasyfikator (prosta rozdzielczość powyżej)
- Kopia zapasowa (proste rozwiązanie powyżej)
- Sprawdzanie schematu (np. rozdzielczość 0.7)

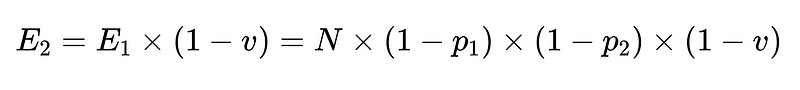
- Na koniec walidator negatywny (n = dokładność 0.6 na przykład)
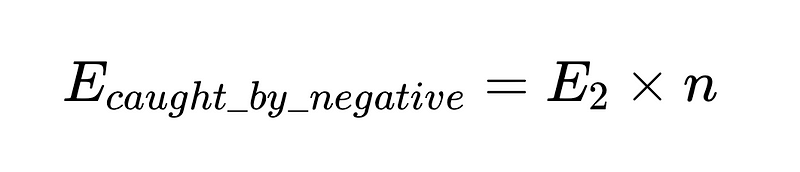
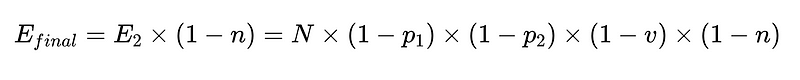
Aby umieścić to w kodzie (Kompletny magazyn), możemy użyć Python podstawowy:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESŁącząc te operacje z logiką, Boolean Mówiąc prościej, możemy uzyskać podobną dokładność i pewność każdej odpowiedzi:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Logika decyzyjna: wyjaśnienie krok po kroku
Krok 1: Kiedy system kontroli jakości zawodzi
if not validation_result:Oznacza to: „Jeśli nasz ekspert ds. kontroli jakości (audytor) odrzuci wstępną analizę, nie należy jej ufać”. System próbuje wówczas wykorzystać opinię zapasową. Jeśli ta również nie przejdzie weryfikacji, sygnalizuje sprawę do weryfikacji przez eksperta. To działanie gwarantuje, że nie będzie on polegał na niedokładnych danych.
Mówiąc prościej: „Jeśli coś jest nie tak z naszą pierwszą odpowiedzią, wypróbujmy metodę awaryjną. Jeśli nadal mamy wątpliwości, poprośmy o interwencję eksperta”. Dzięki temu złożone przypadki będą obsługiwane prawidłowo.
Krok 2: Rozwiąż rozbieżności
if negative_check == 'no' and primary_result['call_type'] is not None:Ten krok sprawdza konkretny typ rozbieżności: „Nasz moduł sprawdzający pasywność wskazuje, że nie powinno być żadnego typu połączenia, ale nasz analityk fundamentalny i tak znalazł typ”.
W takich przypadkach system opiera się na analityku rezerwowym, aby osiągnąć punkt rentowności:
- Jeżeli analityk ds. kopii zapasowych stwierdzi, że nie ma określonego typu zgłoszenia, zostaje ono przekazane do człowieka.
- Jeżeli analityk rezerwowy zgadza się z analitykiem głównym ← Akceptacja została dokonana, ale ze średnim zaufaniem
- Jeśli analityk rezerwowy ma inny typ połączenia ← jest ono przekazywane do osoby
Można to porównać do stwierdzenia: „Jeśli jeden ekspert twierdzi, że »tego nie da się sklasyfikować«, a inny twierdzi, że tak, potrzebujemy rozstrzygającego dogrywki lub ludzkiego sędziego”. Ten mechanizm jest niezbędny, aby zapewnić dokładną klasyfikację typów zgłoszeń i ograniczyć potencjalne błędy.
Krok 3: Kiedy eksperci się zgodzą
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Gdy zarówno główny, jak i zapasowy analityk niezależnie dojdą do tego samego wniosku, system przypisuje mu etykietę „wysoki poziom ufności” – jest to najlepszy scenariusz. Ta idealna sytuacja ma miejsce, gdy wiele analiz jednoznacznie się zgadza.
Mówiąc prościej: „Jeśli dwóch różnych ekspertów niezależnie od siebie dojdzie do tego samego wniosku, stosując różne metody, możemy być niemal pewni, że ich wniosek jest prawidłowy”. Stanowi to konsensus ekspertów, silny wskaźnik dokładności i wiarygodności.
Krok 4: Przetwarzanie domyślne
Jeśli żaden ze szczególnych warunków nie ma zastosowania, system domyślnie przyjmuje wynik głównego analityka ze „średnim” poziomem ufności. Jeśli główny analityk nie jest w stanie określić rodzaju zgłoszenia, oznacza sprawę do weryfikacji przez wyspecjalizowanego analityka.
Znaczenie tego podejścia w ograniczaniu błędów
Logika ta przyczynia się do budowy silnego systemu poprzez:
- Zmniejszanie liczby wyników fałszywie dodatnichSystem daje wysoki poziom pewności tylko wtedy, gdy zgadzają się różne metody, co znacznie zmniejsza liczbę fałszywych alarmów.
- Odkrywanie sprzecznościGdy różne części systemu różnią się od siebie, zaufanie maleje lub sprawa jest kierowana do recenzentów, co gwarantuje, że żaden potencjalny problem nie zostanie pominięty.
- Inteligentna eskalacjaRecenzenci zajmują się wyłącznie tymi przypadkami, które naprawdę wymagają ich wiedzy specjalistycznej. Dzięki temu zwiększa się efektywność procesu recenzji i zmniejsza się obciążenie działu kadr.
- Oznaczenie zaufaniaWyniki uwzględniają poziom ufności systemu, dzięki czemu kolejne procesy mogą inaczej traktować wyniki o wysokim i średnim poziomie ufności, co jest kluczowe dla podejmowania świadomych decyzji.
To podejście jest podobne do sposobu, w jaki elektronika wykorzystuje redundantne obwody i mechanizmy głosowania, aby zapobiec awariom systemu spowodowanym błędami. W systemach AI, ten typ przemyślanej logiki łączenia może znacząco zmniejszyć liczbę błędów, jednocześnie efektywnie wykorzystując ludzkich recenzentów tylko tam, gdzie wnoszą największą wartość. Zapewnia to zarówno optymalizację zasobów, jak i redukcję błędów, co przekłada się na większą niezawodność i dokładność systemu.
Przykład
W 2015 roku Departament Wodny Miasta Filadelfia opublikował Statystyki połączeń klientów według kategorii. Rozumienie rozmów z klientami to bardzo powszechny proces realizowany przez agentów. Zamiast zlecać każdemu klientowi odsłuchiwanie rozmowy przez człowieka, agent może ją znacznie szybciej odsłuchać, wyodrębnić informacje i skategoryzować je do dalszej analizy danych. W przypadku gospodarki wodnej jest to istotne, ponieważ im szybciej zostaną zidentyfikowane krytyczne problemy, tym szybciej będzie można je rozwiązać.
Możemy przeprowadzić eksperyment. Użyłem dużego modelu językowego (LLM) do wygenerowania fałszywych transkryptów rozmów telefonicznych, o których mowa, zadając pytanie: „Mając poniższą kategorię, wygeneruj skróconą wersję tej rozmowy telefonicznej: Poniżej zamieszczono kilka przykładów wraz z pełnym plikiem. Tutaj:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Teraz możemy przeprowadzić eksperyment, stosując bardziej tradycyjną ocenę, wykorzystując jako sędziego duży model językowy (Pełna implementacja tutaj):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typePrzekazując do dużego modelu językowego (LLM) tylko tekst, możemy wyizolować prawdziwą wiedzę o klasie z wyodrębnionej, zwróconej klasy i ją porównać.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultPo uruchomieniu tego na całym syntetycznym zestawie danych przy użyciu Claude 3.7 Sonnet (najnowszego modelu w chwili pisania tego tekstu) uzyskano bardzo wysoką wydajność, a 91% zgłoszeń zostało prawidłowo sklasyfikowanych:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Gdybyśmy byli prawdziwymi połączeniami i nie wiedzielibyśmy wcześniej, do jakiej kategorii należą, musielibyśmy przeanalizować wszystkich 100 połączeń telefonicznych, aby znaleźć 9 błędnie sklasyfikowanych połączeń.
Stosując nasz potężny obwód podejmowania decyzji powyżej, otrzymujemy podobne wyniki dokładności wraz z Pewność siebie W tych odpowiedziach. W tym przypadku ogólna dokładność wynosi 87%, ale nasze odpowiedzi o wysokim poziomie pewności mają dokładność na poziomie 92.5%.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Potrzebujemy 100% dokładności w naszych odpowiedziach o wysokim poziomie pewności, więc wciąż mamy wiele do zrobienia. To podejście pozwala nam na głębsze zbadanie powód Niedokładność odpowiedzi o wysokim poziomie pewności. W tym przypadku słabe twierdzenia i proste możliwości weryfikacji nie uwzględniają wszystkich problemów, co prowadzi do błędów klasyfikacji. Możliwości te można iteracyjnie udoskonalać, aby osiągnąć 100% dokładność odpowiedzi o wysokim poziomie pewności.
Udoskonalenia systemu filtrowania w celu zwiększenia zaufania do wyników
Obecny system klasyfikuje odpowiedzi jako „wysokie prawdopodobieństwo”, gdy analitycy główni i rezerwowi są zgodni. Aby osiągnąć większą dokładność, musimy bardziej selektywnie podchodzić do tego, co uznajemy za „wysokie prawdopodobieństwo”.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Dodanie dodatkowych kryteriów kwalifikacyjnych pozwoli nam uzyskać mniej wyników o „wysokim poziomie ufności”, ale będą one dokładniejsze. To ulepszenie systemu filtrowania ma na celu zmniejszenie błędów i zwiększenie wiarygodności danych klasyfikowanych jako wysokiej jakości.
Dodatkowe techniki weryfikacji: zwiększanie dokładności analizy
Oto kilka innych pomysłów na usprawnienie procesu walidacji i analizy danych:
Analizator trzeciorzędnyDodanie trzeciej, niezależnej metody analizy. Metoda ta stanowi dodatkową warstwę walidacji, porównując wyniki dwóch różnych metod analizy z wynikami trzeciej metody, zapewniając większą dokładność i zmniejszając ryzyko wystąpienia błędów.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Historyczne dopasowywanie wzorcówPorównaj wyniki z wynikami historycznie poprawnymi (np. wyszukiwanie wektorowe). Ta technika wykorzystuje wiarygodne dane historyczne jako punkt odniesienia i porównuje z nimi bieżące wyniki, aby zidentyfikować wszelkie odchylenia lub niespójności. Można ją traktować jako swego rodzaju „pamięć” analityczną, pomagającą wykryć anomalie lub nieoczekiwane zdarzenia.
if similarity_to_known_correct_cases(primary_result) > 0.95:Testowanie antagonistyczneZastosuj niewielkie zmiany do danych wejściowych i sprawdź, czy klasyfikacja pozostaje stabilna. To podejście ma na celu przetestowanie odporności i solidności systemu klasyfikacji poprzez wystawienie go na niewielkie zmiany danych. Jeśli system jest bardzo wrażliwy na te zmiany, może to wskazywać na potencjalne słabości lub błędy.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Ogólny wzór interwencji człowieka w systemie ekstrakcji LLM
Pełne wyprowadzenie jest dostępne tutaj..
- N = Całkowita liczba egzekucji (w naszym przykładzie 10 000)
- p_1 = dokładność parsera bazowego (w naszym przykładzie 0.8)
- p_2 = dokładność parsera zapasowego (w naszym przykładzie 0.8)
- v = skuteczność walidatora schematu (w naszym przykładzie 0.7)
- n = skuteczność sprawdzania negatywów (0.6 w naszym przykładzie)
- H = liczba wymaganych interwencji człowieka
- E_final = ostateczne niewykryte błędy
- m = liczba niezależnych audytorów
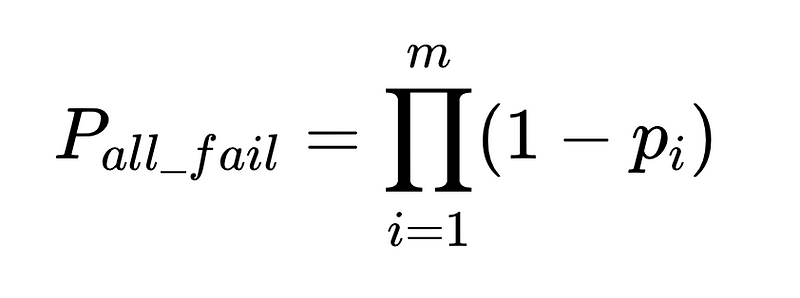
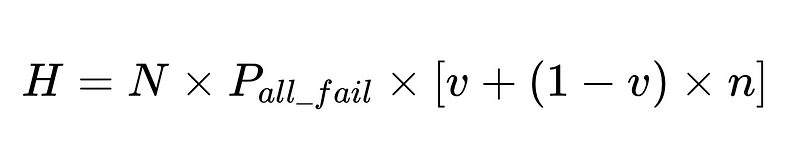
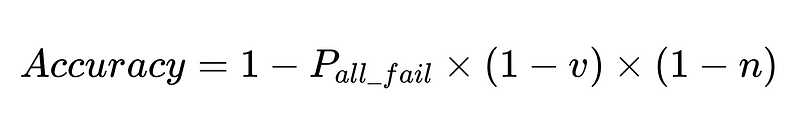
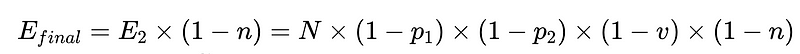
Optymalny projekt systemu
Równanie to ujawnia kluczowe informacje na temat dokładności systemu przetwarzania języka naturalnego (NLP):
- Dodanie parserów zmniejsza obciążenie, ale poprawia ogólną dokładność.
- Dokładność systemu jest ograniczona przez:
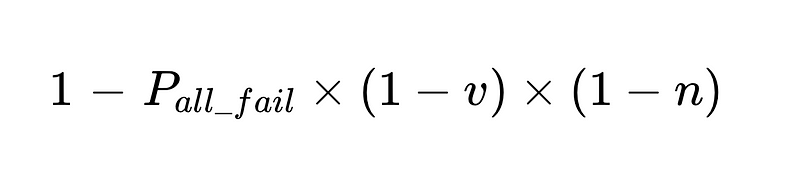
- Interwencje człowieka są proporcjonalne Bezpośrednio Łącznie N wykonań.
Na przykład:
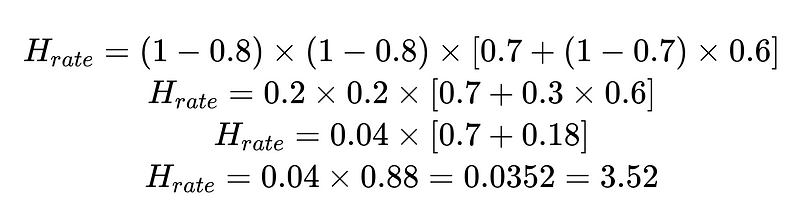
Możemy wykorzystać obliczony wskaźnik interwencji człowieka (H_rate) do śledzenia skuteczności naszego rozwiązania w czasie rzeczywistym. Jeśli H_rate zacznie rosnąć powyżej 3.5%, wiemy, że system zawodzi. Jeśli H_rate stale spada poniżej 3.5%, wiemy, że nasze optymalizacje działają zgodnie z oczekiwaniami.
funkcja kosztu
Możemy również utworzyć funkcję kosztową, która pomoże nam zoptymalizować nasz system. Funkcja kosztowa to potężne narzędzie analityczne do oceny wyników finansowych systemu i identyfikacji potencjalnych obszarów poprawy.
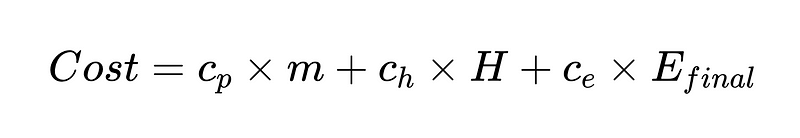
Gdzie:
- c_p = koszt działania na parser (w naszym przykładzie 0.10 USD)
- m = liczba wykonań parsera (w naszym przykładzie 2 * N)
- H = liczba przypadków wymagających interwencji człowieka (352 w naszym przykładzie)
- c_h = koszt jednej interwencji człowieka (na przykład 200 USD: 4 godziny po 50 USD/godzinę)
- c_e = koszt jednego niewykrytego błędu (np. 1000 USD)
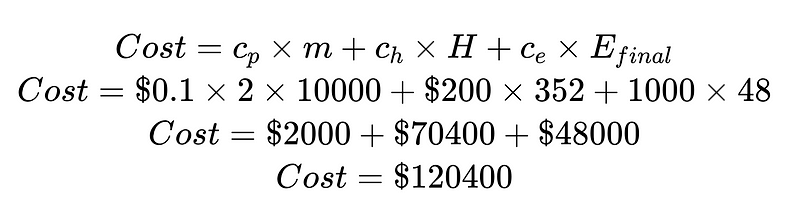
Dzieląc koszt przez koszt interwencji ludzkiej i koszt niewykrytych błędów, możemy ulepszyć cały system. W tym przykładzie, jeśli koszt interwencji ludzkiej (70 400 USD) jest niepożądany i wysoki, możemy skupić się na zwiększeniu wiarygodności wyników. Jeśli koszt niewykrytych błędów (48 000 USD) jest niepożądany i wysoki, możemy wprowadzić analizatory składni Plus, aby zmniejszyć wskaźnik niewykrytych błędów.
Oczywiście funkcje kosztów są najbardziej użyteczne jako sposób badania sposobów poprawy sytuacji, które opisują.
W powyższym scenariuszu, aby zmniejszyć liczbę niewykrytych błędów, E_final o 50%, gdzie
- p1 i p2 = 0.8,
- v = 0.7 i
- n = 0.6
Mamy trzy opcje:
- Dodanie nowego parsera gramatycznego o dokładności 50% i uwzględnienie go jako parsera wtórnego. Należy pamiętać, że wiąże się to z pewnym kompromisem: koszt uruchomienia parserów gramatycznych Plus rośnie wraz ze wzrostem kosztów interwencji człowieka.
- Ulepszenie obecnych parserów o 10% każdy. Może to być możliwe lub niemożliwe ze względu na złożoność zadania, jakie wykonują te parsery.
- Usprawnienie procesu audytu o 15%. Ponownie, zwiększa to koszty ze względu na interwencję człowieka.
Przyszłość zaufania do sztucznej inteligencji: budowanie zaufania poprzez ekstremalną precyzję
W miarę jak systemy AI są coraz bardziej zintegrowane z kluczowymi aspektami biznesu i społeczeństwa, dążenie do optymalnej dokładności będzie stawać się coraz ważniejsze, szczególnie w krytycznych zastosowaniach. Stosując te inspirowane układami scalonymi podejścia do podejmowania decyzji w AI, możemy budować systemy, które nie tylko skalują się efektywnie, ale także zyskują głębokie zaufanie, wynikające wyłącznie z konsekwentnej i niezawodnej wydajności. Przyszłość nie leży w potężniejszych, indywidualnych modelach, lecz w starannie zaprojektowanych systemach, które łączą wiele perspektyw ze strategicznym nadzorem człowieka.
Tak jak elektronika cyfrowa ewoluowała od zawodnych komponentów do komputerów, którym powierzamy nasze najważniejsze dane, tak samo systemy AI podążają podobną drogą. Ramy opisane w tym artykule stanowią wzór dla tego, co ostatecznie stanie się standardową architekturą dla SI o znaczeniu krytycznym – systemów, które nie tylko obiecują niezawodność, ale matematycznie ją gwarantują. Pytanie nie brzmi już, czy potrafimy budować systemy SI o niemal idealnej dokładności, ale jak szybko potrafimy wdrożyć te zasady w naszych najważniejszych aplikacjach.
Możliwość dodawania komentarzy nie jest dostępna.