

Ocena wydajności destylowanych modeli DeepSeek-R1 w GPQA przy użyciu Ollama i prostych ocen z OpenAI
Skonfiguruj i uruchom test porównawczy GPQA-Diamond na lokalnie destylowanych modelach DeepSeek-R1, aby ocenić ich możliwości wnioskowania.
Wprowadzenie najnowszego modelu DeepSeek-R1 Zyskało ono szerokie uznanie w globalnej społeczności AI. Osiągnęło przełom porównywalny z modelami wnioskowania z Meta i OpenAI, a dokonało tego w ułamku czasu i przy znacznie niższych kosztach.
Ale jak, pomijając nagłówki i szum medialny w internecie, możemy ocenić możliwości wnioskowania modelu za pomocą uznanych benchmarków? To ważne pytanie dla ekspertów w dziedzinie sztucznej inteligencji.
Interfejs użytkownika Głębokie poszukiwanie Ułatwia to eksplorację ich możliwości, ale ich programowe wykorzystanie zapewnia głębszy wgląd i płynniejszą integrację z rzeczywistymi aplikacjami. Zrozumienie, jak te modele działają lokalnie, zapewnia również lepszą kontrolę i dostęp offline.

W tym artykule przyjrzymy się, jak korzystać z Ollama و proste ewaluacje z OpenAI Aby ocenić możliwości wnioskowania modeli DeepSeek-R1 wyodrębnionych na podstawie benchmarku GPQA-diament Znane. To kryterium jest uważane za jedno z najważniejszych narzędzi oceny modeli sztucznej inteligencji w dziedzinie rozumowania logicznego.
Tobie Link do repozytorium GitHub Do tego artykułu dołączono:
(1) Jakie są modele rozumowania?
Modele wnioskowania, takie jak DeepSeek-R1 i modele serii o firmy OpenAI (np. o1, o3), to duże modele językowe (LLM) trenowane z wykorzystaniem uczenia przez wzmacnianie w celu przeprowadzania wnioskowania. Modele te stanowią najnowocześniejsze narzędzia sztucznej inteligencji, stanowiąc szczyt ewolucji w zakresie zdolności maszyn do rozumowania i rozwiązywania złożonych problemów.
Modele rozumowania charakteryzują się głębokim namysłem przed udzieleniem odpowiedzi, generując długi ciąg myśli wewnętrznych. Doskonale sprawdzają się w rozwiązywaniu złożonych problemów, programowaniu, rozumowaniu naukowym i wieloetapowym planowaniu przepływów pracy agentów. Te możliwości czynią je niezbędnymi w takich dziedzinach jak zaawansowane tworzenie oprogramowania, badania naukowe i automatyzacja złożonych procesów.
(2) Czym jest model DeepSeek-R1?
DeepSeek-R1 to najnowocześniejszy model języka programowania typu „large language model” (LLM) o otwartym kodzie źródłowym, zaprojektowany specjalnie dla Zaawansowane rozumowanie. Złożono w styczniu 2025 r. w artykule badawczym "DeepSeek-R1: Zwiększanie mocy wnioskowania w dużych modelach językowych poprzez uczenie przez wzmacnianie"DeepSeek-R1 to pionierski model w dziedzinie sztucznej inteligencji.
Model ten opiera się na architekturze dużego modelu językowego (LLM) zawierającej 671 miliardów parametrów i został wytrenowany przy użyciu rozległego uczenia wzmacniającego (RL) zgodnie z następującą ścieżką:
- Dwa etapy rozszerzenia mają na celu odkrycie ulepszonych wzorców rozumowania i dostosowanie ich do ludzkich preferencji.
- Dwa etapy nadzorowanego dostrajania stanowią zalążek możliwości modelu w zakresie wnioskowania i niewnioskowania.
Dla przykładu, DeepSeek wytrenował dwa modele:
- Pierwszy model, DeepSeek-R1-Zero, to model wnioskowania trenowany przy użyciu uczenia wzmacniającego, który generuje dane do trenowania drugiego modelu, DeepSeek-R1.
- Osiąga się to poprzez tworzenie śladów wnioskowania, z których tylko wysokiej jakości wyniki są zachowywane na podstawie ich końcowych rezultatów.
- Oznacza to, że w przeciwieństwie do większości modeli, przykłady uczenia się przez wzmacnianie (RL) w tym procesie szkoleniowym nie są tworzone przez ludzi, lecz generowane przez sam model.
W rezultacie model ten osiągnął wydajność porównywalną z wiodącymi modelami, takimi jak Model o1 firmy OpenAI W zadaniach takich jak matematyka, programowanie i złożone rozumowanie.
(3) Zrozumienie procesu destylacji i destylowanych modeli z DeepSeek-R1
Oprócz pełnego modelu udostępnili również na zasadzie open source sześć mniejszych, gęstych modeli (zwanych również DeepSeek-R1) o różnych rozmiarach (1.5B, 7B, 8B, 14B, 32B, 70B), wyodrębnionych z DeepSeek-R1 na podstawie Qwen أو Lama Jako model podstawowy.
Destylacja Jest to technika, w której mniejszy model („uczeń”) jest trenowany tak, aby powtórzył wyniki większego, wydajniejszego modelu, który został wcześniej wyszkolony („nauczyciel”).
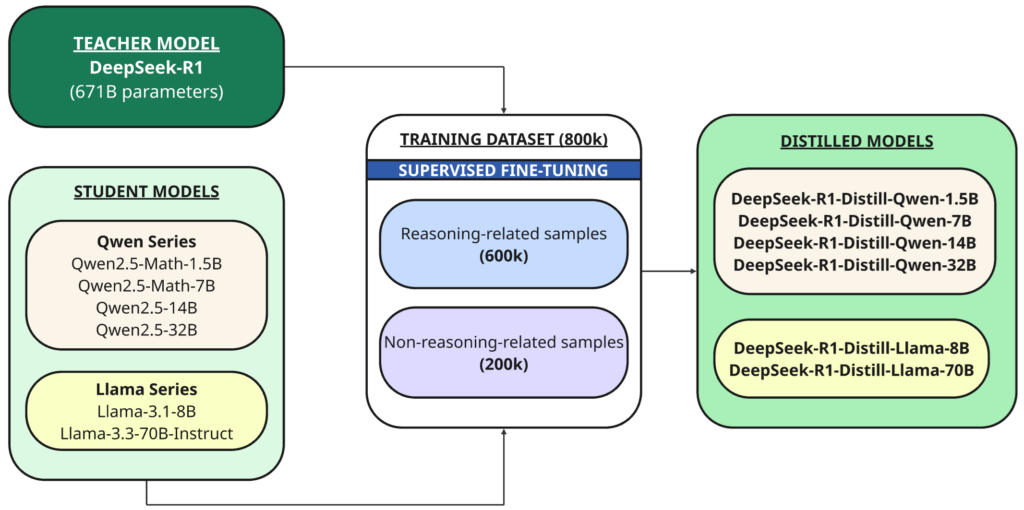
W tym przypadku nauczycielem jest model 1B DeepSeek-R671, a uczniami sześć modeli wyodrębnionych przy użyciu tego bazowego modelu open source:
- Qwen2.5 — Matematyka-1.5B
- Qwen2.5 — Matematyka-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lama-3.1 — 8B
- Llama-3.3 — 70B-Instrukcja
DeepSeek-R1 został użyty jako model nauczyciela do wygenerowania 800,000 XNUMX próbek szkoleniowych, mieszanki próbek wnioskowania i niewnioskowania, do destylacji przez nadzorowane dostrajanie Do modeli podstawowych (1.5B, 7B, 8B, 14B, 32B i 70B).
Dlaczego więc w ogóle zajmujemy się destylacją?
Celem jest przeniesienie możliwości wnioskowania większych modeli, takich jak DeepSeek-R1 671B, do mniejszych i bardziej wydajnych modeli. Dzięki temu mniejsze modele będą mogły obsługiwać złożone zadania wnioskowania, działając szybciej i efektywniej pod względem zasobów.
Co więcej, DeepSeek-R1 ma ogromną liczbę parametrów (671 miliardów), przez co trudno go uruchomić na większości urządzeń konsumenckich.
Nawet najmocniejszy MacBook Pro, z maksymalną pamięcią zunifikowaną wynoszącą 128 GB, nie jest w stanie obsłużyć modelu o parametrach 671 miliardów.
Dzięki temu opracowane modele dają możliwość wdrożenia ich na urządzeniach o ograniczonych zasobach obliczeniowych.
osiągnięty Nielenistwo Niezwykłe osiągnięcie polegające na kwantyzacji oryginalnego modelu DeepSeek-R1, liczącego 671 miliardów parametrów, do zaledwie 131 GB – imponująca redukcja rozmiaru o 80%. Jednak zapotrzebowanie na 131 GB pamięci VRAM pozostaje istotną barierą, szczególnie dla programistów pracujących na urządzeniach o ograniczonych zasobach. To osiągnięcie stanowi istotny krok w kierunku udostępnienia dużych modeli AI szerszemu gronu użytkowników.
(4) Wybór optymalnego modelu destylowanego
Do wyboru jest sześć różnych rozmiarów modeli destylatów, przy czym wybór właściwego modelu zależy w dużej mierze od możliwości lokalnego sprzętu.
Dla użytkowników posiadających wydajne procesory graficzne lub CPU, którym zależy na maksymalnej wydajności, idealne są większe modele DeepSeek-R1 (32B i większe) – nawet wersja kwantowa 671B jest wykonalna.
Jeśli jednak zasoby są ograniczone lub wolisz szybszy czas budowy (jak ja), lepszym wyborem będą mniejsze, destylowane warianty, takie jak 8B lub 14B. To równoważy wydajność i wymagania dotyczące zasobów.
W tym projekcie wykorzystam uproszczony model DeepSeek-R1. Qwen-14B, co odpowiada napotkanym ograniczeniom sprzętowym. Ten model (14B) stanowi doskonały kompromis między dokładnością i szybkością, dzięki czemu idealnie pasuje do mojego środowiska programistycznego.
(5) Kryteria oceny zdolności wnioskowania dużych modeli językowych
Duże modele językowe (LLM) są zazwyczaj oceniane za pomocą standardowych metryk, które mierzą ich wydajność w różnych zadaniach, takich jak rozumienie języka, generowanie kodu, wykonywanie instrukcji i odpowiadanie na pytania. Typowe przykłady obejmują metryki takie jak: MMLU، Ć HumanEval، Ć MGSMTe wskaźniki są niezbędne do oceny możliwości dużych modeli językowych.
Aby zmierzyć zdolność dużego modelu językowego do rozumowania, potrzebujemy bardziej wymagających testów porównawczych, które koncentrują się na rozumowaniu, wykraczając poza powierzchowne zadania. Oto kilka typowych przykładów, które koncentrują się na ocenie zaawansowanych zdolności rozumowania:
(i) Egzamin AIME 2024: Matematyka konkursowa
- Przygotować Amerykański egzamin z matematyki na zaproszenie (AIME) 2024 Solidny punkt odniesienia służący ocenie możliwości dużych modeli językowych (LLM) w rozumowaniu matematycznym.
- Ten egzamin stanowi poważne wyzwanie w matematyce konkursowej, stawiając złożone, wieloetapowe zadania. Egzamin sprawdza zdolność dużych modeli językowych do rozumienia złożonych pytań, stosowania zaawansowanego rozumowania i wykonywania precyzyjnych manipulacji symbolicznych. AIME to ważny miernik oceny umiejętności rozwiązywania złożonych problemów matematycznych.
(ii) Codeforces – Kodeks konkurencji
- Wstań Standard Codeforces Ocena zdolności wnioskowania dużego modelu językowego (LLM) z wykorzystaniem rzeczywistych problemów programistycznych z Codeforces, platformy znanej z wyzwań algorytmicznych. Codeforces jest uważane za złoty standard w ocenie możliwości modeli sztucznej inteligencji w rozwiązywaniu złożonych problemów.
- Te problemy testują zdolność modelu dużego języka (LLM) do rozumienia złożonych instrukcji, przeprowadzania rozumowania logicznego i matematycznego, planowania rozwiązań wieloetapowych oraz generowania poprawnego i wydajnego kodu. Wymagają one dogłębnego zrozumienia algorytmów i struktur danych, a także umiejętności przełożenia problemu na kod wykonywalny.
(iii) Diament GPQA – pytania naukowe na poziomie doktoratu
- GPQA-Diamond to wybrany podzbiór Najtrudniejsze pytania Ze standardu GPQA (Pytania i odpowiedzi z fizyki dla studentów studiów podyplomowych) Najszerszy, zaprojektowany specjalnie po to, by poszerzać możliwości modeli LLM w zakresie wnioskowania na zaawansowanych tematach na poziomie doktoranckim. Ten benchmark stanowi realne wyzwanie dla zdolności sztucznej inteligencji do rozumienia i wnioskowania złożonych pojęć naukowych.
- Podczas gdy GPQA obejmuje zestaw pytań dla absolwentów opartych na założeniach koncepcyjnych i obliczeniach, GPQA-Diamond izoluje tylko najtrudniejsze pytania i te, które wymagają intensywnego rozumowania.
- To kryterium jest uważane za „odporne na Google”, co oznacza, że trudno na nie odpowiedzieć nawet przy nieograniczonym dostępie do internetu. To sprawia, że jest to cenne narzędzie do oceny zdolności dużych modeli językowych do niezależnego rozumowania.
- Oto przykład pytania GPQA-Diamond:
### GPQA Diamond – Przykładowe pytanie (biologia molekularna) Komórka eukariotyczna wyewoluowała mechanizm przekształcania makrocząsteczek budulcowych w energię. Proces ten zachodzi w mitochondriach, które są komórkowymi fabrykami energii. W serii reakcji redoks energia z pożywienia jest magazynowana pomiędzy grupami fosforanowymi i wykorzystywana jako uniwersalna waluta komórkowa. Cząsteczki nasycone energią są transportowane z mitochondriów, aby służyć we wszystkich procesach komórkowych. Odkryłeś nowy lek przeciwcukrzycowy i chcesz zbadać, czy ma on wpływ na mitochondria. Przeprowadziłeś szereg eksperymentów z linią komórkową HEK293. Który z poniższych eksperymentów nie pomoże Ci odkryć roli Twojego leku w mitochondriach: (A) Ekstrakcja mitochondriów przez różnicowe wirowanie z następową analizą kolorymetryczną glukozy (B) Cytometria przepływowa po znakowaniu 2.5 µM jodkiem 5,5',6,6'-tetrachloro-1,1',3,3'-tetraetylobenzimidazolilkarbocyjaniny (C) Transformacja komórek za pomocą rekombinowanej lucyferazy i odczyt luminometru po dodaniu 5 µM lucyferyny do supernatantu (D) Mikroskopia fluorescencyjna konfokalna po barwieniu komórek Mito-RTP
W tym projekcie Jako standard wnioskowania stosujemy GPQA-Diamond., tak jak go używałem OpenAI و DeepSeek Wybór GPQA-Diamond jako kryterium oceny w celu oceny modeli wnioskowania stanowi dowód jego złożoności i znaczenia w obszarze rozwoju sztucznej inteligencji.
(6) Narzędzia używane
W tym projekcie wykorzystujemy głównie Ollama و proste-ewaluacje Od OpenAI. Ollama to potężna platforma do lokalnego uruchamiania dużych modeli językowych, natomiast simple-evals zapewnia platformę do oceny wydajności tych modeli.
(i) Ollama
Ollama To narzędzie typu open source, które upraszcza uruchamianie dużych modeli językowych (LLM) na naszych komputerach lub na serwerze lokalnym. Olama to idealna platforma do lokalnego uruchamiania modeli AI.
Działa jako menedżer i środowisko wykonawcze, obsługując zadania takie jak pobieranie i konfiguracja środowiska. Pozwala to użytkownikom na interakcję z tymi modelami bez konieczności stałego połączenia z internetem lub korzystania z usług w chmurze. Zarządzanie lokalnymi modelami dużych języków (LLM) jest kluczową funkcją Olama.
Obsługuje wiele rozbudowanych modeli językowych open source, w tym DeepSeek-R1, i jest kompatybilny międzyplatformowo z systemami macOS, Windows i Linux. Dodatkowo oferuje prostą konfigurację, minimalny nakład pracy i efektywne wykorzystanie zasobów. Ollama pozwala wykorzystać moc sztucznej inteligencji bezpośrednio na Twoim urządzeniu.
WażnyUpewnij się, że Twój komputer lokalny ma: Dostępność GPU Dla Ollama, ponieważ znacznie przyspiesza to wydajność i sprawia, że kolejne operacje pomiarowe są bardziej wydajne pod względem wykorzystania procesora. Uruchom polecenie
nvidia-smiW terminalu sprawdź, czy jednostka przetwarzania grafiki została wykryta. Dzięki temu masz pewność, że możliwości urządzenia będą w pełni wykorzystane do wydajnego uruchamiania modeli.
(ii) Biblioteka OpenAI simple-evals do oceny modeli językowych
Przygotować proste-ewaluacje Lekka biblioteka zaprojektowana do oceny modeli językowych z wykorzystaniem metodologii ewaluacji bezstratnej z podpowiedziami myślowymi. Zawiera popularne testy porównawcze, takie jak MMLU, MATH, GPQA, MGSM i HumanEval, i ma na celu symulację rzeczywistych przypadków użycia w celu oceny wydajności modeli sztucznej inteligencji w złożonych zadaniach wnioskowania.
Niektórzy z Was mogą znać najpopularniejszą i najbardziej wszechstronną bibliotekę ewaluacyjną OpenAI o nazwie Oceny, co różni się od prostych evals.
W rzeczywistości strona wskazuje README Specyfikacja simple-evals nie ma na celu zastąpienia biblioteki. Oceny.
Dlaczego więc stosujemy proste metody ewaluacyjne?
Prosta odpowiedź brzmi: proste-ewaluacje Zawiera wbudowane teksty oceniające dla standardów wnioskowania, na których się skupiamy (takich jak GPQA), których brakuje w bibliotece. Oceny.
Ponadto nie znalazłem żadnych innych narzędzi ani platform, poza simple-evals, które zapewniałyby bezpośredni i natywny sposób nauki języka. Python Do wdrażania wielu ważnych standardów, takich jak GPQA, szczególnie podczas współpracy z Ollamą.
(7) Wyniki oceny
W ramach oceny wybrałem: 20 losowych pytań Z zestawu pytań GPQA-Diamond składającego się ze 198 pytań do pracy Formularz 14B DestylarzNa odpowiedź potrzeba było łącznie 216 minut, czyli około 11 minut.
Wynik był nieco rozczarowujący, ponieważ zdobył 10% Tylko, że jest to wynik znacznie niższy od podanego wyniku 73.3% dla modelu 1B DeepSeek-R671.
Główny problem, który zauważyłem, polega na tym, że podczas intensywnego wewnętrznego rozumowania, Model często nie dawał żadnej odpowiedzi (np. zwracając kody wnioskowania jako ostatnie wiersze wyników) lub podawał odpowiedź, która nie pasowała do oczekiwanego formatu wyboru wielokrotnego (np. odpowiedź: A).
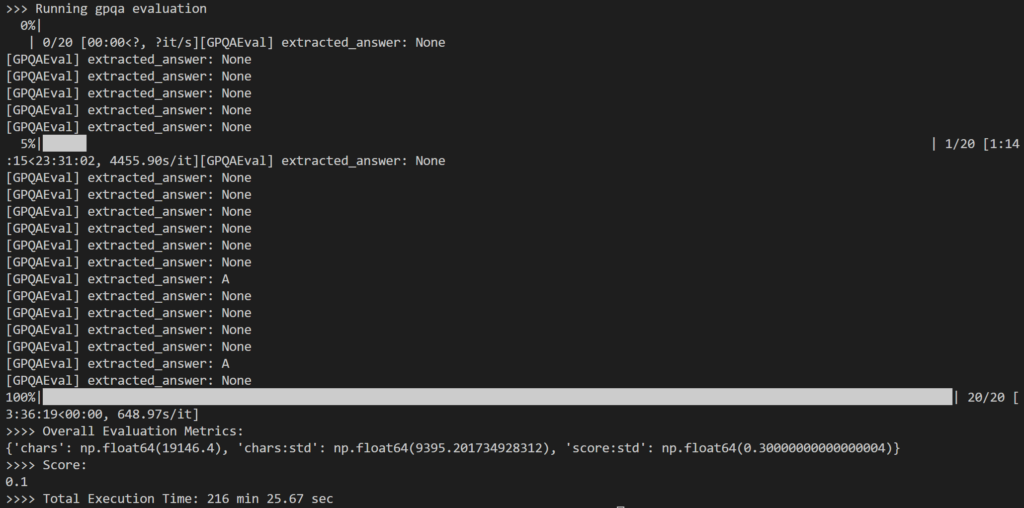
Jak pokazano powyżej, wiele wyników wyglądało następująco: None Ponieważ logika wyrażeń regularnych w simple-evals nie mogła wykryć oczekiwanego wzorca odpowiedzi w odpowiedzi LLM.
Chociaż to Rozumowanie podobne do ludzkiego Było to ciekawe doświadczenie, ponieważ spodziewałem się lepszych wyników pod względem dokładności udzielania odpowiedzi na pytania.
Widziałem też użytkowników online, którzy wspominali, że nawet większy model 32B nie działa tak dobrze, jak o1. To wzbudziło wątpliwości co do przydatności destylowanych modeli wnioskowania, zwłaszcza gdy mają one problemy z generowaniem poprawnych odpowiedzi pomimo generowania długich wnioskowań.
Jednak GPQA-Diamond jest bardzo wymagającym benchmarkiem, więc modele te mogą być nadal przydatne w przypadku prostszych zadań wnioskowania. Ich niższe wymagania obliczeniowe ułatwiają również ich implementację.
Co więcej, zespół DeepSeek zalecił przeprowadzenie wielu testów i uśrednienie wyników jako część procesu testowania wydajności, ale pominąłem to ze względu na ograniczenia czasowe.
(8) Szczegółowy przewodnik krok po kroku
Do tej pory omówiliśmy podstawowe koncepcje i najważniejsze wnioski.
Jeśli jesteś gotowy na praktyczne, techniczne doświadczenie, ta sekcja oferuje dogłębne omówienie wewnętrznych mechanizmów i krok po kroku omówienie implementacji. Ten praktyczny przewodnik techniczny zapewni Ci kompleksowe zrozumienie działania systemu.
Aby wyświetlić (lub skopiować) Repozytorium GitHub Companion Poniżej znajdziesz wymagania dotyczące konfiguracji środowiska wirtualnego. Tutaj.
(i) Konfiguracja początkowa – Ollama
Zacznijmy od pobrania Ollama. Odwiedź
Strona pobierania Ollama, wybierz swój system operacyjny i postępuj zgodnie z instrukcjami instalacji.
Po zakończeniu instalacji uruchom Ollamę, klikając dwukrotnie aplikację Ollama (dla systemów Windows i macOS) lub uruchamiając polecenie ollama serve W terminalu.
(ii) Konfiguracja początkowa – proste ewaluacje OpenAI
Konfiguracja simple-evals jest dość unikalna.
Chociaż simple-evals prezentuje się jako biblioteka, Brak plików __init__.py W repozytorium oznacza, że nie jest ono ustrukturyzowane jak właściwy pakiet Pythona., co prowadzi do błędów importu po lokalnym klonowaniu repozytorium. Oznacza to, że nie jest to standardowy pakiet Pythona w rozumieniu powszechnie używanym w inżynierii oprogramowania.
Ponieważ nie jest on również publikowany w PyPI i brakuje standardowych plików pakietowych, takich jak setup.py أو pyproject.tomlNie można go zainstalować za pomocą pipTo stanowi pewne wyzwanie dla nowych programistów.
Na szczęście możemy użyć Podmoduły Git Prostą alternatywą jest to, że moduły te umożliwiają łączenie jednego repozytorium Git w innym, co ułatwia zarządzanie zależnościami.
„`html
Podmoduł Gita pozwala nam włączyć zawartość innego repozytorium Gita do naszego projektu. Pobiera pliki z zewnętrznego repozytorium (takiego jak simple-evals), ale zachowuje ich historię osobno.
Aby wyodrębnić zawartość simple-evals, możesz wybrać jedną z dwóch metod (A lub B):
(a) Jeśli sklonujesz moje repozytorium projektu
Moje repozytorium projektu już zawiera simple-evals Jako podmoduł, więc możesz po prostu uruchomić:
git submodule update --init --recursive(b) Jeśli dodajesz go do nowo utworzonego projektu.
Aby ręcznie dodać simple-evals jako podmoduł, uruchom to:
git submodule add https://github.com/openai/simple-evals.git simple_evalsOgłoszenie: To simple_evals Na koniec (z podkreślać) jest bardzo ważne. Określa nazwę folderu, a użycie myślnika zamiast niego (tj. prostego-evals) może później powodować problemy z importem.
Ostatni krok (dla obu metod)
Po pobraniu zawartości repozytorium należy utworzyć plik. __init__.py Opróżnij folder simple_evals Nowo utworzony plik można zaimportować jako moduł. Możesz go utworzyć ręcznie lub użyć następującego polecenia:
touch simple_evals/__init__.py(iii) Pobieranie modelu DeepSeek-R1 za pomocą Ollama
Następnym krokiem jest pobranie lokalnie destylowanego modelu wybranego przez Ciebie (na przykład 14B) za pomocą tego polecenia:
Listę dostępnych modeli DeepSeek-R1 można znaleźć na stronie Ollama. TutajAby uzyskać najlepszą wydajność, zaleca się korzystanie z najnowszej wersji szablonu.
ollama pull deepseek-r1:14b(Czwarty) Określ ustawienia
Parametry definiujemy w pliku ustawień YAML, jak pokazano poniżej:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Nazwa modelu (zgodna z listą modeli Ollama) MODEL_TEMPERATURE: 0.6 # Ustaw pomiędzy 0.5 i 0.7 dla DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
Temperatura modelu jest ustawiona na 0.6 (W porównaniu z typową wartością domyślną 0). Jest to zgodne z zaleceniami użytkowania DeepSeek, które sugerują zakres temperatur od 0.5 do 0.7 (zalecana jest wartość 0.6). Aby zapobiec nieskończonym powtórzeniom lub niespójnym wynikom. To ustawienie jest konieczne, aby poprawić jakość wyników i zapewnić ich spójność.
Nie przegap okazji, aby sprawdzić Unikalne i interesujące rekomendacje dotyczące użytkowania DeepSeek-R1 – szczególnie w testach porównawczych – aby zapewnić optymalną wydajność podczas korzystania z modeli DeepSeek-R1.
EVAL_N_EXAMPLES Ten parametr służy do ustawienia liczby pytań z całego zestawu 198 użytych w ocenie. Parametr ten jest niezbędny do dostosowania procesu oceny do dostępnych zasobów i konkretnych celów testu.
(v) Konfigurowanie kodu Samplera
Aby obsługiwać modele językowe oparte na Ollamie w ramach struktury simple-evals, tworzymy niestandardową klasę opakowującą o nazwie OllamaSampler I trzymaj to w sobie utils/samplers/ollama_sampler.pySampler jest niezbędnym elementem testowania i oceniania wydajności modeli językowych.
# utils/samplers/ollama_sampler.py import ollama class OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
W tym kontekście oznacza to próbnik (Sampler) Klasa Pythona, która generuje dane wyjściowe z modelu języka na podstawie zadanego monitu. To narzędzie jest kluczowe dla zapewnienia, że model generuje zróżnicowane i reprezentatywne odpowiedzi.
Ponieważ samplery w simple-evals obejmują tylko dostawców takich jak OpenAI i Claude, potrzebujemy klasy samplera, która zapewnia interfejs zgodny z Ollamą. Zapewnia to bezproblemową integrację z frameworkiem ewaluacyjnym.
Wstań OllamaSampler Wyodrębnia pytanie GPQA, przesyła je do modelu z określoną temperaturą i zwraca odpowiedź w postaci zwykłego tekstu. Temperatura jest ważnym parametrem kontrolującym losowość wyników.
Metoda uwzględniona _pack_message Aby zapewnić, że format wyjściowy jest zgodny z oczekiwaniami skryptów ewaluacyjnych w simple-evals. Zapewnia to spójność i łatwość analizy.
6. Utwórz skrypt ewaluacyjny
Poniższy kod pokazuje, jak skonfigurować implementację oceny w pliku. main.py, w tym wykorzystanie kategorii GPQAEval Z biblioteki simple-evals do uruchamiania testów porównawczych GPQA.
funkcjonować run_eval() To konfigurowalne narzędzie ewaluacyjne, które testuje duże modele językowe (LLM) za pomocą platformy Ollama, porównując je z testami porównawczymi, takimi jak GPQA. Funkcja ta jest niezbędna do dokładnej oceny wydajności modelu.
# main.py def run_eval(): start_time = time.time() # Załaduj plik konfiguracyjny config = load_config("config/config.yaml") # Zainicjuj sampler Ollama (otoczka wokół czatu Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Wybierz klasę oceny do użycia na podstawie EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Running {eval_benchmark} evaluation") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Domyślnie 1 "num_examples": config["EVAL_N_EXAMPLES"], # Ustaw na 20 "variant": config["GPQA_VARIANT"], # Podzbiór GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Utwórz instancję i uruchom odpowiednią ocenę evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Wykonaj ocenę za pomocą samplera end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Oblicz całkowity czas # Zwrócone wyniki to EvalResult, który zawiera listę SingleEvalResult i zagregowane metryki print(">>>> Ogólne metryki oceny:", results.metrics) print(">>>> Wynik:", results.score) print(f">>>> Całkowity czas wykonania: {int(minuty)} min {sekundy:.2f} sek") if __name__ == "__main__": # Uruchom wykonanie oceny GPQA run_eval()
Funkcja ładuje ustawienia z pliku konfiguracyjnego, ustawia odpowiednią klasę ewaluacyjną z simple-evals i uruchamia model w jednolitym procesie ewaluacji. Jest ona zapisywana w pliku. main.py, który można wykonać za pomocą polecenia python main.pyDzięki temu proces oceny jest spójny i powtarzalny.
Postępując zgodnie z powyższymi krokami, udało nam się pomyślnie skonfigurować i uruchomić test porównawczy GPQA-Diamond na zmodyfikowanym modelu DeepSeek-R1. Proces ten dostarcza cennych informacji na temat możliwości modelu.
Podsumowując
W tym artykule badamy, w jaki sposób możemy połączyć narzędzia takie jak Ollama i simple-evals firmy OpenAI, aby eksplorować i oceniać modele wyodrębnione z DeepSeek-R1, ze szczególnym uwzględnieniem Ocena wydajności dużych modeli językowych.
Wydestylowane modele mogą jeszcze nie dorównywać pierwotnemu modelowi o 671 miliardach parametrów w wymagających testach wnioskowania, takich jak GPQA-Diamond. Pokazują jednak, jak destylacja może poszerzyć zakres możliwości wnioskowania modeli dużego języka (LLM). Poprawa dostępu do dużych modeli językowych Jest to jeden z najważniejszych celów w tym obszarze.
Pomimo niższej wydajności w przypadku złożonych zadań na poziomie doktoratu, te mniejsze warianty mogą nadal znaleźć zastosowanie w mniej wymagających scenariuszach, torując drogę do efektywnego wdrożenia lokalnego na szerszej gamie urządzeń. Przyczynia się to do Wdrażaj duże modele językowe lokalnie Skutecznie.
Możliwość dodawania komentarzy nie jest dostępna.