

Sztuczna inteligencja oszukała nas za pomocą gry na telefonie... a efekt był szokujący!
Modele generowania obrazów oparte na sztucznej inteligencji (AI) dynamicznie się rozwijają, ale nadal często generują one obrazy o wątpliwej jakości. Ponieważ łatwo założyć, że problemem są ludzkie podpowiedzi, postanowiłem sprawdzić, czy sztuczna inteligencja działa wydajniej, korzystając wyłącznie z podpowiedzi generowanych przez AI. Generowanie obrazów przez AI, takie jak ChatGPT i Gemini, w dużej mierze opiera się na jakości i dokładności podpowiedzi. Czy wyniki różniłyby się w przypadku użycia podpowiedzi automatycznych? To właśnie sprawdzimy w tym eksperymencie.
![]()
Zasady eksperymentowania
Kiedy kilka lat temu pojawiły się modele generowania obrazów przez sztuczną inteligencję, wszyscy myśleliśmy, że będą one sygnałem ostrzegawczym dla wszystkich pracujących w mediach wizualnych. Ale tak się nie stało. Choć potrafią tworzyć niezwykle realistyczne obrazy, obrazy generowane przez sztuczną inteligencję często zaliczają się do kategorii nieprzewidywalnych, zwłaszcza jeśli potrzebujesz czegoś bardziej złożonego (na przykład sztuczna inteligencja ma problemy z generowaniem obrazów dłoni).
Można obwiniać za ten problem same modele sztucznej inteligencji, albo ludzkie niedociągnięcia i nasze niespójne umiejętności w formułowaniu roszczeń. Naturalnym sposobem na sprawdzenie, kto jest odpowiedzialny, jest sprawdzenie, czy modele generujące obrazy działają lepiej, gdy wprowadza się wygenerowane roszczenia.

Czy sztuczna inteligencja (AI) może dać nam nowe spojrzenie na historyczne momenty?
Aby przetestować tę hipotezę, użyję Gemini do wygenerowania serii komunikatów, które unikają nazwy obiektu lub obrazu, który próbuję utworzyć. Pomoże to zweryfikować, jak dobrze sztuczna inteligencja „odczytuje” instrukcje. Co prawda, istnieje możliwość, że model będzie w dużym stopniu pod wpływem danych, na których został wytrenowany (zwłaszcza podczas rekonstrukcji istniejących obrazów), ale taka jest rzeczywistość, jak mówią młodzi ludzie.
Narzędziem, którego będę używał do tworzenia obrazów, będzie Bing (tak, Bing nadal istnieje) Image Creator, który opiera się na DALL-E 3. Aby przetestować ten model, zacznę od prostych kształtów, a następnie przejdę do bardziej złożonych obrazów w miarę postępu eksperymentu.
Jeśli kiedykolwiek korzystałeś z ChatGPT lub podobnych narzędzi, wiesz już, jak nieskuteczne potrafią być niektóre z ich odpowiedzi. Podobnie było z podpowiedziami, które formularz wyświetlił mi podczas testu. Dlatego postanowiłem ograniczyć się do 500 znaków, aby zachować spójność podpowiedzi.
Jak sztuczna inteligencja radzi sobie z prostymi kształtami?
Zacznijmy od prostego kwadratu. Poprosiłem Geminiego, żeby opisał kwadrat bez nadawania mu nazwy, i oto, co wymyślił:
„Czworokąt, którego wszystkie boki są równej długości. Każdy kąt wewnętrzny ma dokładnie 90 stopni. Jest to czworokąt foremny, którego przeciwległe boki są równoległe.”
Po wprowadzeniu opisu do DALL-E uzyskałem następujące wyniki:
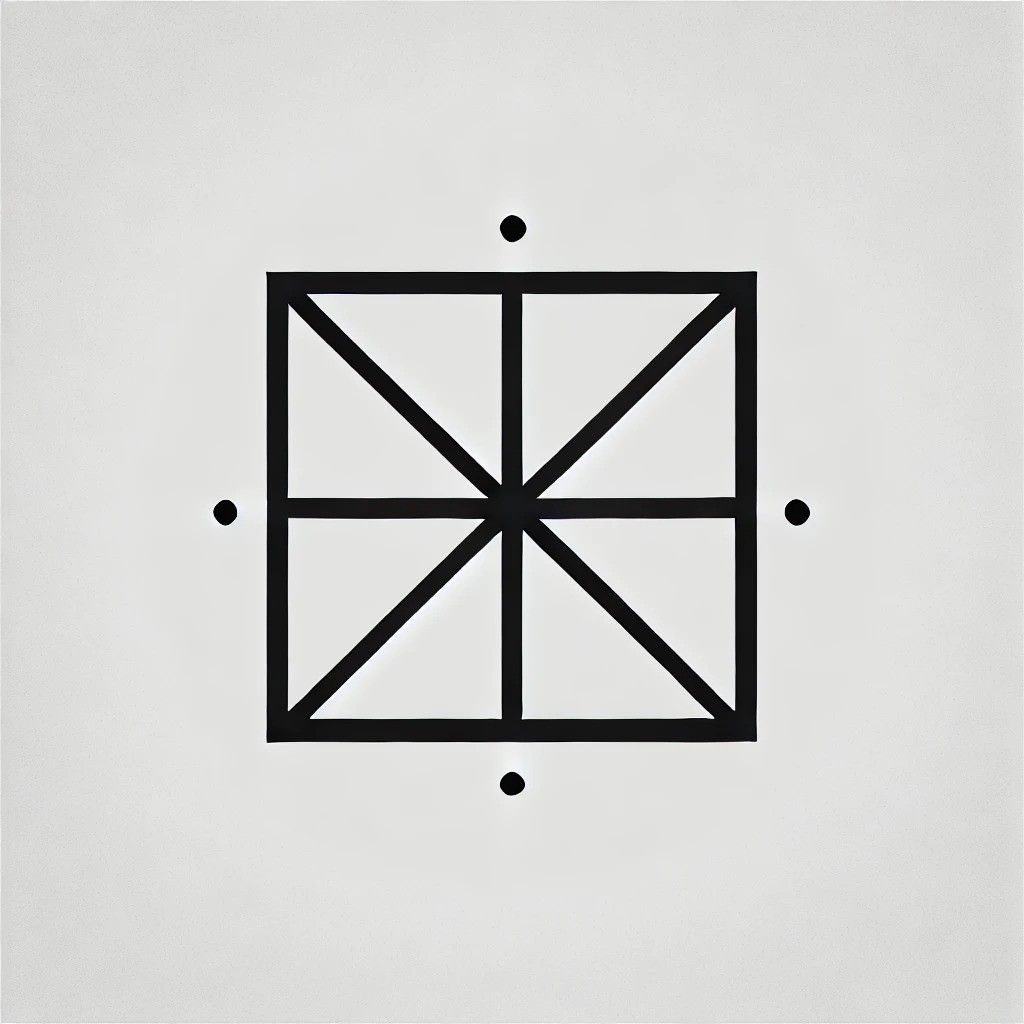
To kwadrat, okej, chociaż moim zdaniem trochę zbyt geometryczny. Czas zwiększyć poziom trudności, więc poprosiłem sztuczną inteligencję o narysowanie sześcianu.
Trójwymiarowa figura o sześciu identycznych ścianach. Każda ściana jest czworokątem foremnym o czterech równych bokach i czterech kątach prostych. Ma 12 krawędzi równej długości i 8 wierzchołków. Wszystkie kąty w tej figurze są proste.
Wyniki są niesamowite:

Pamiętacie, co mówiliśmy o nieprzewidywalności modeli sztucznej inteligencji? Otóż DALL-E stworzył kostkę, ale trochę ją pomylił i zrobił z niej kostkę Rubika. Choć całkowicie unikał dokładnego określenia, sztuczna inteligencja popełniła częściowy błąd – możemy to przypisać popularności węgierskiej gry logicznej.
Perspektywa AI na fotografię z ludźmi
Postawa kostki pokazuje, że nawet przy precyzyjnym, „bezstronnym” opisie, sztuczna inteligencja może błędnie zinterpretować nawet proste instrukcje. Sprawdźmy zatem, jak radzi sobie z generowanymi przez sztuczną inteligencję opisami klasycznych obrazów, takich jak „Matka migrująca” Dorothei Lange. Oto oryginalny obraz:

Na zdjęciu widać kobietę z twarzą wyrytą w wyrazie zmartwienia, odwracającą wzrok od obiektywu. Otaczają ją dzieci, z twarzami zasłoniętymi lub odwróconymi. Jej dłoń spoczywa blisko twarzy, wyrażając wyczerpanie i cierpienie. Scena sugeruje ubóstwo i niedostatek. Kobieta ma znoszone ubranie, a całość jest ponura, podkreślając powagę jej sytuacji.
Oto interpretacja słynnego zdjęcia autorstwa DALL-E:

Bardzo blisko! Ale nie do końca trafne, ponieważ DALL-E wyraźnie pominął frazę „Otaczają ją jej dzieci, ich twarze są zasłonięte lub odwrócone.Zamiast tego, aby „matka” przyłożyła rękę do twarzy, rolę tę przejęło jedno z dzieci.
Spróbujmy czegoś bardziej złożonego. Być może widziałeś słynne zdjęcie „Lunch na szczycie wieżowca”:

„Jedenastu mężczyzn siedzi wysoko na stalowej belce, jedząc lunch, z nogami zwisającymi swobodnie. Belka wisi nad rozległym miastem. Mężczyźni wydają się zrelaksowani, pomimo ekstremalnego wzrostu. Mają na sobie ubrania robocze, a scena została sfilmowana z nieco niższego kąta, co podkreśla ich wzrost”.
To genialne twierdzenie przyniosło genialne rezultaty:

Gdy zignorujemy klasyczne cechy charakterystyczne obrazów generowanych przez sztuczną inteligencję (identyczne garnki i przeskalowane, skopiowane obiekty), ich kompozycja i ogólny charakter stają się wręcz zaskakujące. Nic dziwnego – ten obraz jest nie tylko niezwykle powszechny, ale także znajduje się w domenie publicznej, więc mam subtelne podejrzenie, że DALL-E faktycznie zrekonstruował jego zawartość podczas treningu.
Czy sztuczna inteligencja poradzi sobie ze złożonymi obrazami?
Ponieważ to ostatni „test” w eksperymencie, czas podejść do sprawy poważnie! Choć sztuczna inteligencja jest biegła w manipulowaniu wizerunkami ludzi, często zawodzi w obliczu złożonych i niejednoznacznych scen. A co ze słynnym zdjęciem „Wschodu Ziemi” zrobionym z orbity księżycowej na pokładzie Apollo 8?

„Częściowo oświetlona kula wisi w ciemnej przestrzeni. Mniejsza, szara kula wznosi się nad horyzontem. Większa kula ma niebieskie i białe plamy, symbolizujące wodę i chmury. Wyraźny kontrast między obiema kulami i czernią podkreśla kruchość i izolację mniejszej, wznoszącej się kuli”.
Gemini (a raczej sfera) nie sprawdził się w tym opisie. Z uwagi na jego skrajną abstrakcję, dodałem do tego stwierdzenia frazę „przechwycony z pobliskiej orbity księżycowej”, ale niewiele to pomogło:

To przepiękna, wyrafinowana okładka rockowego albumu, ale nie ma nic wspólnego z „Earthrise”. Aby dopełnić eksperyment, wybrałem jak dotąd najbardziej enigmatyczny obraz – industrialne arcydzieło Edwarda Westona „Aramco Steel”:

„Kadr wypełnia seria okrągłych, przemysłowych, metalowych zbiorników. Ich gładkie i wypukłe formy tworzą powtarzający się wzór. Światło odbija się od powierzchni, podkreślając ich zaokrąglone kształty i tworząc wrażenie objętości. Kompozycja koncentruje się na abstrakcyjnych aspektach obiektów przemysłowych, kładąc nacisk na formę i fakturę, a nie na funkcję. Scena jest prosta i nowoczesna, z silnym naciskiem na światło i cień”.
Wydaje się, że to dobry punkt wyjścia; zobaczmy, czy Dall-E się z nami zgodzi:

Chociaż doceniam element science fiction, obraz w ogóle nie przypomina oryginału. Nie chciałem kończyć eksperymentu w katastrofalny sposób, więc postanowiłem pomóc maszynie, dodając na końcu danych wejściowych frazę „zdjęcie z lat 1920. XX wieku”.
Myślałem, że ten konkretny termin pomoże mi doprecyzować obraz, do którego nawiązuję. Niestety, Dall-E po raz kolejny mnie zawiódł i stworzył kolejną okładkę albumu z rockiem progresywnym:

Wyniki tego eksperymentu były interesujące, a wniosek, jaki z niego wyciągnęliśmy, jest taki, że obrazy generowane przez sztuczną inteligencję są wysoce nieprzewidywalne, zwłaszcza w przypadku bardziej abstrakcyjnych pojęć. Nie ma znaczenia, czy dane wejściowe są generowane przez sztuczną inteligencję i dokładne, czy przez człowieka i niedoskonałe – wyniki wydają się losowe.
Więc następnym razem, gdy będziesz próbował obwiniać siebie i swój styl wprowadzania danych, pamiętaj, że wyniki prawdopodobnie będą dość podobne, nawet jeśli dwa urządzenia komunikują się ze sobą.
Możliwość dodawania komentarzy nie jest dostępna.