

Ocena odbiorców: 27 modeli AI, ChatGPT na 8. miejscu – oto modele, które go przewyższyły
Chociaż świat Sztuczna inteligencja (AI) Choć często może się to wydawać obszarem niespokojnym, za kulisami przeprowadza się zaskakująco dużo analiz, analiz porównawczych i testów — nie tylko przez same firmy, ale także przez grupy powołane w celu ustalenia własnych rankingów.

Grupy te testują wszystko, od zdolności chatbota do wykonywania testów matematycznych,
Utwórz obrazylub podać logiczne wyjaśnienia, a nawet udzielić porady medycznej lub po prostu pokazać, jak bardzo jest inteligentna emocjonalnie.
Podczas tych różnych testów modele demonstrują swoje mocne i słabe strony w różnych obszarach. Na przykład, podczas gdy GPT-5 Wyróżnia się zdolnością do naukowego rozumowania, ale ustępuje takim osobom jak Gemini i Claude w umiejętności przystosowywania się do nowych koncepcji.
Każdy z tych testów mówi nam coś nowego o modelach AI i jest ważny, ponieważ przypomina nam, które narzędzia sprawdzają się najlepiej w różnych scenariuszach. Często jednak brakuje jednej metryki: które modele AI zapewniają najlepsze doświadczenia użytkownika?
System klasyfikacji humanoidalnej
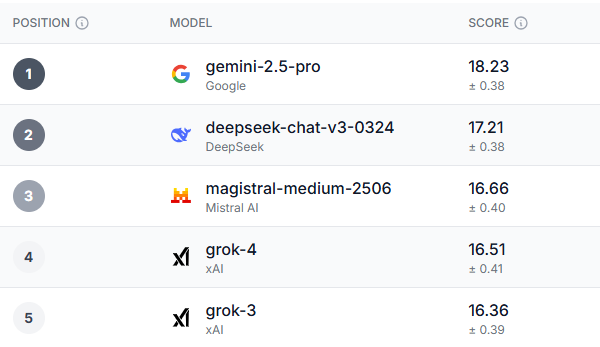
Brytyjska firma technologiczna o nazwie Prolific stworzyła Ranking sztucznej inteligencji o nazwie HumaineZamiast testować zdolność sztucznej inteligencji do wykonywania zadań, Prolific przetestował różne doświadczenia użytkowników przy użyciu tych modeli.
Oceniając doświadczenia 21 352 osób z narzędziami, udało się nie tylko wyłonić zwycięzcę, ale także podzielić wyniki ze względu na wiek, lokalizację (testy przeprowadzono zarówno w Wielkiej Brytanii, jak i w USA) i poglądy polityczne.
Obejmuje to pojedyncze oferty dla:
- Wielka Brytania: Grupy wiekowe
- Wielka Brytania: Rasa
- Wielka Brytania: Poglądy polityczne
- Stany Zjednoczone: Grupy wiekowe
- Stany Zjednoczone: Rasa
- Stany Zjednoczone: Pogląd polityczny
Każdy uczestnik miał okazję do interakcji z dwoma różnymi modelami sztucznej inteligencji, aby je porównać, a następnie poproszono ich o podanie informacji zwrotnej na temat tego, który model wypadł lepiej w każdej interakcji.
W rezultacie wyłoniono zwycięzcę w klasyfikacji generalnej i tabeli liderów za wydajność, a także oddzielne rankingi za podstawowe wykonywanie zadań i rozumowanie, a także zwycięzcę za komunikację, odporność, zaufanie i etykę.
Co pokazują wyniki?

Po gruntownej analizie wyłoniono wyraźnego zwycięzcę, nie tylko w kategorii ogólnej wydajności, ale także w większości podkategorii. Gemini 2.5-Pro wyróżniał się w niemal każdym benchmarku objętym testem.
Młodzi ludzie w wieku 18–34 lat w Wielkiej Brytanii, wyborcy Partii Demokratycznej i osoby powyżej 55. roku życia w USA zgodzili się, że Bliźnięta 2.5 Pro To najlepszy model w ogóle. Jedynym obszarem, w którym wszystkie grupy demograficzne uzyskały wyższą ocenę niż Gemini, było zaufanie, etyka i bezpieczeństwo, i był to Grok-3 – co jest nieco ironicznym odkryciem, biorąc pod uwagę problemy z bezpieczeństwem i etyką, z jakimi borykały się ostatnio modele sztucznej inteligencji.
Co ciekawe, po Gemini pojawiły się trzy modele: Deepseek, Magistral Le Chat i GrokChociaż Deepseek cieszył się znaczną popularnością na początku tego roku, ostatnio stracił na popularności. Z kolei Le Chat, chatbot o mniejszej popularności, ma wierną rzeszę fanów.
Gdzie w tym wszystkim plasuje się światowej sławy ChatGPT? Jest na samym dole listy, na ósmym miejscu z najwyżej ocenianym modelem GPT-4.1. Jeszcze gorzej jest Claude, gdzie cztery jego edycje zajęły odpowiednio jedenaste i dwunaste miejsce w klasyfikacji generalnej.
Co to wszystko oznacza?
Czy to oznacza, że Gemini jest najlepszym chatbotem AI na świecie? Czy to oznacza, że powinieneś porzucić ChatGPT…? Cóż, nie do końca.
Te wyniki niekoniecznie odzwierciedlają wydajność tych modeli. Podczas testów na większości innych metryk, opcje, które zazwyczaj widzimy na górze, to ChatGPT, Gemini, Claude i Grok.
Jest to jednak ważny dodatek do tych testów. Pomagają nam lepiej zrozumieć sztuczną inteligencję z perspektywy ludzkiego doświadczenia. Na przykład Le Chat nie osiąga wysokich wyników w standardowych testach porównawczych, ale często jest uznawany za doskonały wybór pod względem doświadczenia i wiarygodności.
Chociaż wyniki Anthropic i OpenAI nie osiągnęły tak wysokiego poziomu w tej rundzie testów, Gemini i Grok zaliczyły kolejny dobry występ. Obie firmy często osiągają wysokie wyniki w standardowych testach porównawczych i tak było również w tym przypadku.
Możliwość dodawania komentarzy nie jest dostępna.