

Dlaczego większość modeli ryzyka cyberbezpieczeństwa zawodzi jeszcze przed rozpoczęciem działania
Potrzeba ilościowego myślenia o zagrożeniach cyberbezpieczeństwa
Liderzy cyberbezpieczeństwa stają przed niemożliwymi pytaniami. „Jakie jest prawdopodobieństwo naruszenia bezpieczeństwa w tym roku?”, „Ile to będzie kosztować?” i „Ile powinniśmy wydać, aby temu zapobiec?”.
Jednak większość współczesnych modeli ryzyka nadal opiera się na domysłach, instynkcie i mapach ryzyka oznaczonych kolorami, a nie na danych.
W rzeczywistości znalazłem Badanie PwC dotyczące globalnego zaufania cyfrowego w 2025 r. Tylko 15% organizacji wykorzystuje w znaczącym stopniu ilościowe modelowanie ryzyka.
W tym artykule analizujemy, dlaczego tradycyjne modele ryzyka cyberbezpieczeństwa są nieskuteczne i w jaki sposób zastosowanie prostych narzędzi statystycznych, np. modelowania probabilistycznego, może okazać się lepszym rozwiązaniem.

Dwie główne szkoły myślenia w modelowaniu cyberryzyka
Modele ryzyka cybernetycznego to: Systematyczne ramy lub metody służące do analizowania, oceniania i pomiaru zagrożeń cyberbezpieczeństwa oraz ich potencjalnego wpływu na systemy informatyczne, dane lub przedsiębiorstwa.
Specjaliści ds. bezpieczeństwa informacji w trakcie procesu oceny ryzyka stosują głównie dwie metody modelowania ryzyka: jakościową i ilościową. Ilościowe modelowanie cyberzagrożeń Zaawansowana technika wymagająca specjalistycznej wiedzy.
Jakościowe modele oceny ryzyka
Wyobraź sobie dwa zespoły oceniające to samo ryzyko. Jeden zespół ocenia prawdopodobieństwo ryzyka na 4/5, a wpływ na 5/5. Drugi zespół ocenia je odpowiednio na 3/5 i 4/5. Oba zespoły nanoszą jego pozycję na macierz. Jednak żaden z nich nie potrafi odpowiedzieć na pytanie dyrektora finansowego: „Jakie jest prawdopodobieństwo, że to się faktycznie wydarzy i ile nas to będzie kosztować?”.
Podejście jakościowe opiera się na subiektywnej ocenie ryzyka, opartej przede wszystkim na intuicji oceniającego. Podejście jakościowe zazwyczaj prowadzi do oceny prawdopodobieństwa i wpływu ryzyka w skali porządkowej, takiej jak 1-5.
Następnie ryzyka są umieszczane w macierzy ryzyka, aby ustalić, gdzie plasują się na tej skali porządkowej.
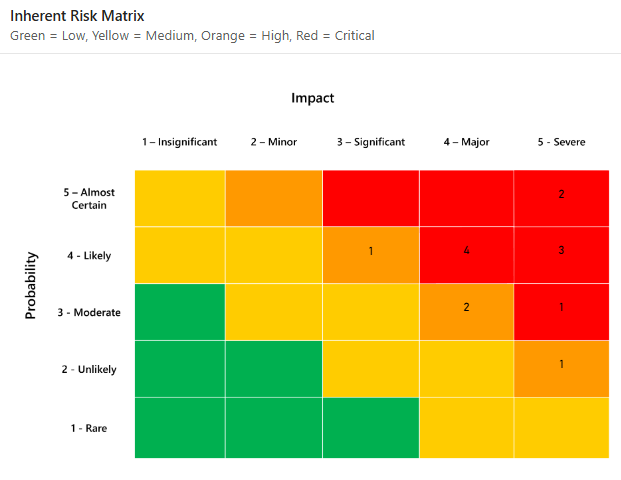
Te dwie skale porządkowe są często mnożone przez siebie, aby ułatwić priorytetyzację najistotniejszych zagrożeń na podstawie prawdopodobieństwa i wpływu. Na pierwszy rzut oka wydaje się to rozsądne, ponieważ powszechnie stosowana definicja ryzyka w bezpieczeństwie informacji brzmi:
[tekst{Ryzyko} = tekst{Prawdopodobieństwo} razy tekst{Wpływ}]
Jednak ze statystycznego punktu widzenia jakościowe modelowanie ryzyka wiąże się z pewnymi bardzo istotnymi ryzykami.
Pierwszym z tych zagrożeń jest stosowanie skal porządkowych. Choć przypisywanie liczb do skal porządkowych stwarza pozory matematycznego wsparcia dla modelu, jest to jedynie iluzja.
Skale porządkowe to po prostu etykiety – nie ma między nimi zdefiniowanej odległości. Odległość między ryzykiem o wpływie „2” a wpływem „3” nie jest policzalna. Zmiana etykiet na skali porządkowej na „A”, „B”, „C”, „D” i „E” nie powoduje żadnej zmiany.
To z kolei oznacza, że nasz wzór na ryzyko jest błędny w przypadku modelowania jakościowego. Nie da się obliczyć prawdopodobieństwa zdarzenia „B” pomnożonego przez efekt zdarzenia „C”.
Kolejną poważną pułapką jest modelowanie niepewności. Modelując cyberryzyko, modelujemy niepewne przyszłe zdarzenia. W rzeczywistości istnieje szereg możliwych rezultatów.
Przeniesienie ryzyka cybernetycznego na pojedyncze szacunki (takie jak „20/25” lub „Wysokie”) nie uwzględnia istotnej różnicy między „najbardziej prawdopodobną roczną stratą wynoszącą 1 milion dolarów” a „istnieje 5% prawdopodobieństwo straty w wysokości 10 milionów dolarów lub więcej”.
Ilościowe modelowanie ryzyka: zaawansowana analiza
Wyobraź sobie zespół przeprowadzający ocenę ryzyka. Oszacowali zakres wyników, od 100 000 do 10 milionów dolarów. Przeprowadzając symulację Monte Carlo, wyliczyli 10% prawdopodobieństwo przekroczenia 1 miliona dolarów strat rocznie i oczekiwanej straty w wysokości 480 000 dolarów. Teraz, gdy dyrektor finansowy pyta: „Jakie jest prawdopodobieństwo, że tak się stanie i ile by to kosztowało?”Zespół może odpowiedzieć, opierając się nie tylko na intuicji, ale i danych.
To podejście przenosi rozmowę z niejasnych klasyfikacji ryzyka na Możliwości i potencjalny wpływ finansowy, język zrozumiały dla kadry kierowniczej.
Jeśli masz wykształcenie statystyczne, jedna koncepcja powinna szczególnie rzucić Ci się w oczy:
Prawdopodobieństwo.
Modelowanie ryzyka cyberbezpieczeństwa w swojej istocie polega na próbie ilościowego określenia prawdopodobieństwa wystąpienia określonych zdarzeń i ich wpływu, jeśli wystąpią. Otwiera to drogę do różnorodnych narzędzi statystycznych, takich jak symulacja Monte Carlo, które pozwalają modelować niepewność znacznie skuteczniej niż miary porządkowe.
Ilościowe modelowanie ryzyka wykorzystuje modele statystyczne do przypisywania stratom wartości w dolarach i modelowania prawdopodobieństwa wystąpienia tych zdarzeń stratowych, odzwierciedlając przyszłą niepewność.
Choć analiza jakościowa może czasami przybliżyć najbardziej prawdopodobny wynik, nie uwzględnia ona pełnego zakresu niepewności, np. rzadkich, ale znaczących zdarzeń, znanych jako „ryzyko długiego ogona”.
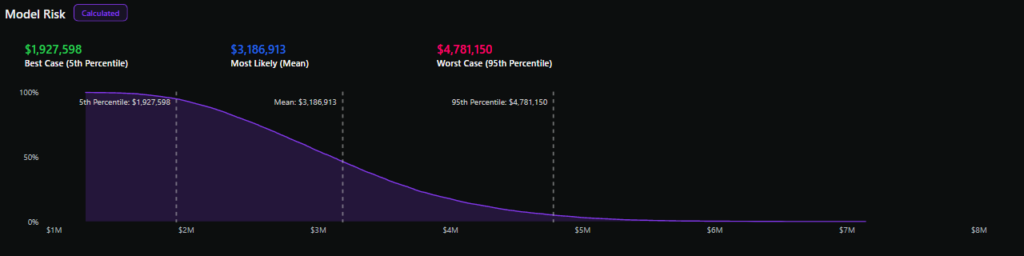
Krzywa nadwyżki strat przedstawia prawdopodobieństwo przekroczenia określonej rocznej kwoty strat na osi Y oraz różne kwoty strat na osi X, co daje linię opadającą.
Wyciągnięcie różnych percentyli z krzywej nadwyżki strat, takich jak 5 percentyl, mediana i 95 percentyl, może dać pogląd na potencjalne roczne straty dla ryzyka z 90% pewnością.
Podczas gdy jednopunktowa ocena analizy jakościowej może przybliżyć najbardziej prawdopodobne ryzyko (w zależności od dokładności osądu oceniających), analiza ilościowa ujmuje niepewność wyników, nawet tych, które są rzadkie, ale nadal możliwe (znane jako „ryzyko długiego ogona”).
Spojrzenie poza cyberzagrożenie: doskonalenie modeli ryzyka w cyberbezpieczeństwie
Aby udoskonalić nasze modele ryzyka w obszarze bezpieczeństwa informacji, musimy spojrzeć na nie z zewnątrz, a konkretnie na techniki stosowane w innych dziedzinach. Modele ryzyka znacząco rozwinęły się w wielu zastosowaniach, takich jak finanse, ubezpieczenia, bezpieczeństwo lotnicze i zarządzanie łańcuchem dostaw. Dziedziny te dostarczają cennych spostrzeżeń, które można wykorzystać w cyberbezpieczeństwie.
Zespoły finansowe wykorzystują modele do zarządzania ryzykiem portfela inwestycyjnego, wykorzystując podobne statystyki bayesowskie. Zespoły ubezpieczeniowe modelują ryzyko za pomocą zaawansowanych modeli aktuarialnych. Branża lotnicza modeluje ryzyko awarii systemów za pomocą modeli probabilistycznych. Zespoły zarządzania łańcuchem dostaw modelują ryzyko za pomocą symulacji probabilistycznej. Te metodologie stanowią solidną podstawę do tworzenia skutecznych modeli cyberryzyka.
Narzędzia już istnieją. Matematyczne podstawy są dobrze znane. Inne branże utorowały drogę. Teraz nadszedł czas, aby cyberbezpieczeństwo wdrożyło ilościowe modele ryzyka, aby podejmować lepsze, bardziej świadome decyzje, udoskonalać strategie cyberbezpieczeństwa i ograniczać potencjalne straty. Wdrożenie tych modeli ilościowych stanowi kluczowy krok w kierunku skuteczniejszego zarządzania cyberryzykiem.
الخلاصة الرئيسية
| Analiza jakościowa | Analiza ilościowa |
| Skale porządkowe (1-5) | Modelowanie probabilistyczne |
| intuicja osobista | dokładność statystyczna |
| Pojedyncze punkty oceny | Rozkłady ryzyka |
| Mapy cieplne i kody kolorów | Krzywe przekroczenia strat |
| Ignoruje rzadkie, ale poważne zdarzenia | Przechwytuje ryzyko długiego ogona |
Możliwość dodawania komentarzy nie jest dostępna.