

Wyjaśnienie: W jaki sposób regularyzacja L1 automatycznie wybiera cechy?
Poznaj proces automatycznego wyboru cech wykonywany przez regularyzację L1 (LASSO).
Selekcja cech to proces wybierania optymalnego podzbioru cech z danego zbioru cech; optymalny podzbiór to taki, który maksymalizuje wydajność modelu w odniesieniu do danego zadania.
Identyfikacja cech może być procesem ręcznym lub raczej jawnym, gdy wykonuje się ją za pomocą metody filtrujące lub metody opakowująceW tych metodach cechy są iteracyjnie dodawane lub usuwane na podstawie ustalonej wartości metryki, która określa, jak ważna jest dana cecha w procesie prognozowania. Metrykami mogą być przyrost informacji, wariancja lub statystyka chi-kwadrat, a algorytm podejmuje decyzję o akceptacji lub odrzuceniu cechy na podstawie ustalonego progu metryki. Warto zauważyć, że metody te nie są częścią fazy uczenia modelu i są wykonywane przed nią.
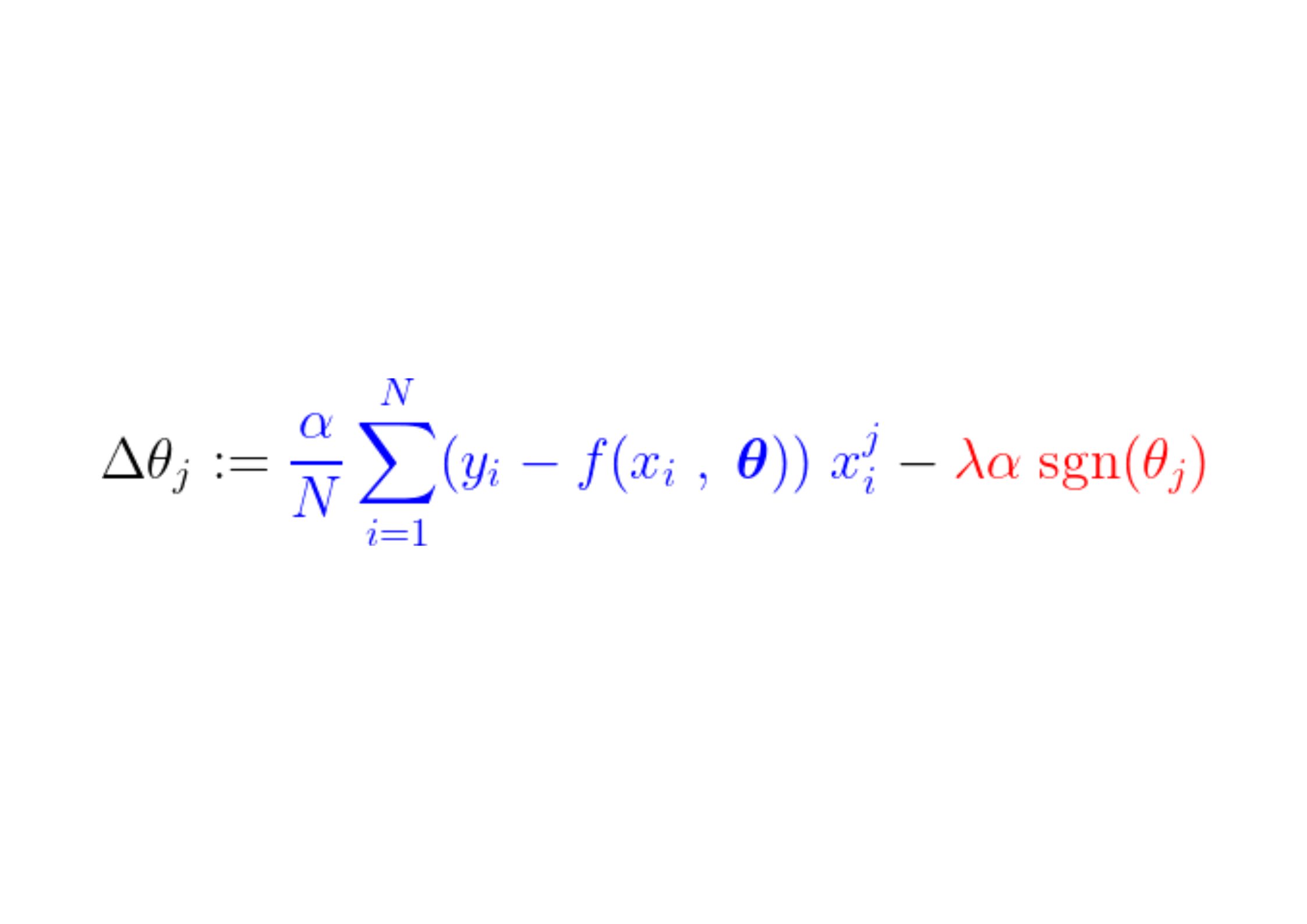
Wstań Metody osadzone Poprzez niejawną identyfikację cech, bez użycia predefiniowanych kryteriów selekcji i wyodrębnianie ich z samych danych treningowych, ten proces identyfikacji cech kluczowych stanowi część fazy treningu modelu. Model uczy się identyfikować cechy i jednocześnie formułować trafne prognozy. W kolejnych sekcjach opiszemy rolę regularyzacji w tym procesie identyfikacji cech kluczowych, koncentrując się na regularyzacji L1 i jej roli w ulepszaniu modeli uczenia maszynowego.
Normalizacja i złożoność modelu: zaawansowane strategie poprawy wydajności
Regularyzacja to proces nakładania kar na złożoność modelu w celu uniknięcia nadmiernego dopasowania i uzyskania uogólnienia zadania.
W tym przypadku złożoność modelu jest analogiczna do jego zdolności adaptacji do wzorców w danych treningowych. Zakładając prosty model wielomianowy wx„w pewnym stopniu”dIm wyższy wynikdW przypadku wielomianów model charakteryzuje się większą elastycznością w wychwytywaniu wzorców w obserwowanych danych. Ta zwiększona elastyczność może prowadzić do zapamiętywania przez model danych treningowych zamiast uczenia się rzeczywistych wzorców, co ogranicza jego zdolność do generalizacji na nowe dane.
Nadmierne dopasowanie i niedostateczne dopasowanie
Próbując dopasować model wielomianowy o stopniu d = 2 W przypadku zbioru próbek treningowych pobranych z wielomianu trzeciego stopnia z pewnym szumem, model nie będzie w stanie odpowiednio uchwycić rozkładu próby. Modelowi po prostu brakuje Elastyczność أو złożoność Niezbędny do modelowania danych generowanych przez wielomiany stopnia 3 (lub wyższego). Model ten nazywa się niedostatecznie wysportowany W danych treningowych. Niedociążenie wskazuje, że model jest zbyt prosty i nie jest w stanie uchwycić podstawowych wzorców w danych.
Pracując na tym samym przykładzie, zakładamy teraz, że mamy model o stopniu d = 6Teraz, przy zwiększonej złożoności, model powinien z łatwością oszacować pierwotny wielomian sześcienny użyty do wygenerowania danych (np. ustawiając współczynniki wszystkich wyrazów o wykładnikach > 3 na 0). Jeśli proces uczenia nie zostanie zakończony w odpowiednim czasie, model będzie nadal wykorzystywał swoją dodatkową elastyczność, aby jeszcze bardziej zmniejszyć błąd i zacząć rejestrować również zaszumione próbki. To znacznie zmniejszy błąd uczenia, ale model teraz… nadmierne dopasowanie Na danych treningowych. Szum będzie się zmieniał w warunkach rzeczywistych (lub podczas testowania), a wszelka wiedza oparta na przewidywaniach będzie osłabiona, co spowoduje wysoki błąd testowania. Przeciążenie oznacza, że model jest zbyt złożony i uczy się na podstawie szumu, a nie rzeczywistego sygnału.
Jak określić optymalną złożoność modelu?
W praktyce często mamy ograniczoną lub żadną wiedzę na temat procesu generowania danych lub rzeczywistego rozkładu danych. Znalezienie optymalnego modelu o odpowiedniej złożoności, który nie będzie nadmiernie lub niedostatecznie dopasowany, stanowi poważne wyzwanie. Wymaga to zastosowania skutecznych metod oceny wydajności modelu i określenia odpowiedniej złożoności, zapewniającej najlepszą równowagę między dokładnością a ogólnością. Stosując odpowiednie metryki i techniki ewaluacji, takie jak walidacja krzyżowa, praktycy mogą zidentyfikować model, który najlepiej sprawdza się na niewidocznych danych, unikając w ten sposób problemów z nadmiernym lub niedostatecznym dopasowaniem.
Jedną z możliwych technik jest rozpoczęcie od wystarczająco solidnego modelu, a następnie zmniejszenie jego złożoności poprzez dobór cech. Im mniej cech, tym mniej złożony jest model.
Jak omówiliśmy w poprzedniej sekcji, selekcja cech może być jawna (metody filtrowania, metody splotu) lub niejawna. Nadmiarowe cechy, które nie są krytyczne dla określenia wartości zmiennej docelowej, muszą zostać wyeliminowane, aby zapobiec uczeniu się przez model wzorców, które nie są ze sobą powiązane. Regularyzacja również realizuje podobne zadanie. Jaki jest zatem związek regularyzacji i selekcji cech z osiągnięciem wspólnego celu, jakim jest optymalna złożoność modelu? Zmniejszenie złożoności w modelach uczenia maszynowego ma kluczowe znaczenie dla poprawy wydajności i uniknięcia nadmiernego dopasowania, na czym koncentrują się zarówno regularyzacja, jak i selekcja cech.
Regularizacja L1 jako wyznacznik cech
Kontynuując nasz model wielomianowy, przedstawiamy go jako funkcję f z danymi wejściowymi xi transakcje θ I stopień d،
![]()
W przypadku modelu wielomianowego można rozważyć każdą potęgę wejścia x_i Jako zaletę można utworzyć wektor o następującej formie:
![]()
Definiujemy również funkcję celu, której minimalizacja prowadzi do optymalnych parametrów. θ* Termin ten obejmuje: regularyzacja (Regulacja), która karze za złożoność modelu.
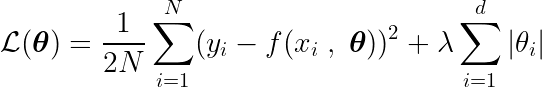
Aby znaleźć minimum tej funkcji, musimy przeanalizować wszystkie punkty krytyczne, czyli punkty, w których pochodna jest równa zero lub nieokreślona.
Pochodną cząstkową można zapisać względem jednego z parametrów, θj, w następujący sposób:
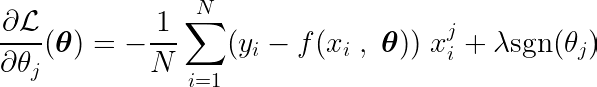
gdzie funkcja jest zdefiniowana znak لى النحو التالي:
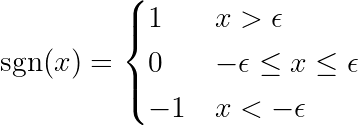
OgłoszeniePochodna funkcji bezwzględnej różni się od funkcji znaku (sgn) zdefiniowanej powyżej. Pierwotna pochodna jest niezdefiniowana dla x = 0. Rozszerzamy definicję, usuwając punkt przegięcia dla x = 0 i czyniąc funkcję różniczkowalną w całym zakresie. Co więcej, frameworki uczenia maszynowego (ML) używają tych rozszerzonych funkcji, gdy obliczenia bazowe obejmują funkcję bezwzględną. Sprawdź to. Połączyć Na forum PyTorch.
Obliczając pochodną cząstkową funkcji celu względem jednego współczynnika θji przyrównując ją do zera, możemy skonstruować równanie łączące optymalną wartość θj Z przewidywaniami, celami i funkcjami.
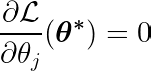
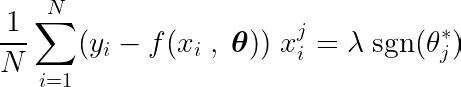
Przyjrzyjmy się powyższemu równaniu. Jeśli założymy, że dane wejściowe i docelowe były skoncentrowane wokół średniej (tj. dane zostały znormalizowane na etapie wstępnego przetwarzania), wówczas wyraz po lewej stronie (LHS) w praktyce reprezentuje zmienność Pomiędzy cechą numer j a różnicą pomiędzy wartością oczekiwaną i docelową.
Kowariancja statystyczna pomiędzy dwiema zmiennymi określa, w jakim stopniu jedna zmienna wpływa na wartość drugiej zmiennej (i odwrotnie).
Funkcja znaku po prawej stronie wymusza na wariancji po lewej stronie przyjęcie tylko trzech wartości (ponieważ funkcja znaku zwraca tylko -1, 0 i 1). Jeśli funkcja j Niepotrzebne i nie mające wpływu na prognozy, wariancja będzie bliska zeru, co spowoduje odpowiedni współczynnik θj* Zero. Powoduje to usunięcie funkcji z modelu. Ten proces pomaga zmniejszyć złożoność i poprawić wydajność modelu.
Wyobraź sobie funkcję sygnału jako kanion wyrzeźbiony przez wodę. Możesz przejść przez kanion (czyli koryto rzeki), ale aby się wydostać, napotkasz ogromne bariery lub strome zbocza. Regularyzacja L1 tworzy efekt „progowy” podobny do gradientu funkcji straty. Gradient musi być wystarczająco silny, aby przebić się przez bariery lub osiągnąć zero, co ostatecznie spowoduje, że wartość parametru wyniesie zero.
Aby podać bardziej realistyczny przykład, rozważmy zbiór danych zawierający próbki pochodzące z linii prostej (model dwuparametrowy) z pewnym dodanym szumem. Optymalny model powinien mieć nie więcej niż dwa parametry; w przeciwnym razie dostosuje się do szumu w danych (z dodatkową swobodą/potęgą wielomianu). Zmiana parametrów o wyższej mocy w modelu wielomianowym nie wpływa na różnicę między wartościami docelowymi a przewidywaniami modelu, zmniejszając tym samym jego wariancję z cechą.
W trakcie procesu uczenia, stały krok jest dodawany/odejmowany od gradientu funkcji straty. Jeśli gradient funkcji straty (MSE – średni błąd kwadratowy) jest mniejszy niż stały krok, współczynnik ostatecznie osiągnie 0. Zwróć uwagę na poniższe równanie, które obrazuje, jak współczynniki są aktualizowane za pomocą metody gradientu prostego:

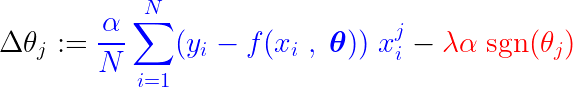
Jeśli niebieska część powyżej jest mniejsza niż λα, która sama w sobie jest bardzo małą liczbą, Δθj To prawie stały krok. λαSygnał dla tego kroku (część czerwona) zależy od: sgn(θj), którego wyjście zależy od θjJeśli wartość jest θj Pozytywny, czyli większy niż ε, ten sgn(θj) równa się 1, co oznacza Δθj W przybliżeniu równe -λα, popychając go w kierunku zera.
Aby stłumić stały krok (część czerwona), który powoduje zerowanie parametru, gradient funkcji straty (część niebieska) musi być większy niż rozmiar kroku. Aby uzyskać większy gradient funkcji straty, wartość cechy musi znacząco wpływać na wynik modelu.
W ten sposób cecha, a dokładniej jej odpowiedni parametr, którego wartość nie jest związana z wynikami modelu, zostaje zerowana przez regularyzację L1 w trakcie treningu.
Dalsze czytanie i wnioski
- Aby uzyskać więcej informacji na ten temat, zamieściłem pytanie na Reddicie r/MachineLearning iPodejmować właściwe kroki Zawiera różne interpretacje, które możesz chcieć przeczytać.
- Madiyar Aitbayev ma również Ciekawy blog Odpowiada na to samo pytanie, ale podaje wyjaśnienie geometryczne.
- Blog Brian King wyjaśnia koncepcję organizacji z perspektywy probabilistycznej.
- To Dyskusja Na stronie CrossValidated wyjaśnia, dlaczego norma L1 zachęca do stosowania modeli rzadkich. Blog Szczegółowy artykuł Mukula Ranjana wyjaśnia, dlaczego norma L1 zachęca do tego, aby transakcje osiągnęły zero, a norma L2 nie.
„Regulacja L1 wybiera cechy” to proste stwierdzenie, z którym zgadza się większość osób uczących się uczenia maszynowego, bez zagłębiania się w jego wewnętrzne mechanizmy. Niniejszy blog jest próbą przedstawienia czytelnikom mojego rozumienia i modelu mentalnego, aby w intuicyjny sposób odpowiedzieć na to pytanie. W przypadku sugestii i wątpliwości proszę o kontakt mailowy pod adresem Moja strona internetowaKontynuuj naukę i miej wspaniały dzień!
Możliwość dodawania komentarzy nie jest dostępna.