

Iluzja ChatGPT jest prawdziwa: czy modele sztucznej inteligencji mają więcej halucynacji?
Firma OpenAI opublikowała w zeszłym tygodniu raport badawczy szczegółowo opisujący różne testy wewnętrzne i wyniki swoich modeli o3 i o4-mini. Główne różnice między tymi nowszymi modelami a wczesnymi wersjami ChatGPT, które widzieliśmy w 2023 roku, to ich zaawansowane wnioskowanie i możliwości multimodalne. O3 i o4-mini mogą generować obrazy, przeszukiwać sieć, automatyzować zadania, zapamiętywać wcześniejsze rozmowy i rozwiązywać złożone problemy. Jednak te ulepszenia wydają się również wiązać z nieoczekiwanymi efektami ubocznymi, co wymaga kompleksowych ocen w celu zapewnienia bezpiecznego korzystania ze sztucznej inteligencji.
Co testy mówią o częstości występowania halucynacji w modelach sztucznej inteligencji?
OpenAI ma konkretny test Model używany do pomiaru częstości halucynacji nazywa się PersonQA. Obejmuje on zestaw faktów o ludziach, z których można się „uczyć”, oraz zestaw pytań dotyczących tych osób, na które należy odpowiedzieć. Dokładność modelu jest mierzona na podstawie prób odpowiedzi. W zeszłym roku model o1 osiągnął wskaźnik dokładności na poziomie 47% i wskaźnik halucynacji na poziomie 16%.
Ponieważ te dwie wartości nie sumują się do 100%, możemy założyć, że pozostałe odpowiedzi nie były ani trafne, ani halucynacyjne. Model może czasami stwierdzić, że nie wie lub nie może zlokalizować informacji, może w ogóle nie formułować żadnych twierdzeń i zamiast tego podać istotne informacje lub może popełnić drobny błąd, którego nie można zakwalifikować jako pełnoprawnej halucynacji.
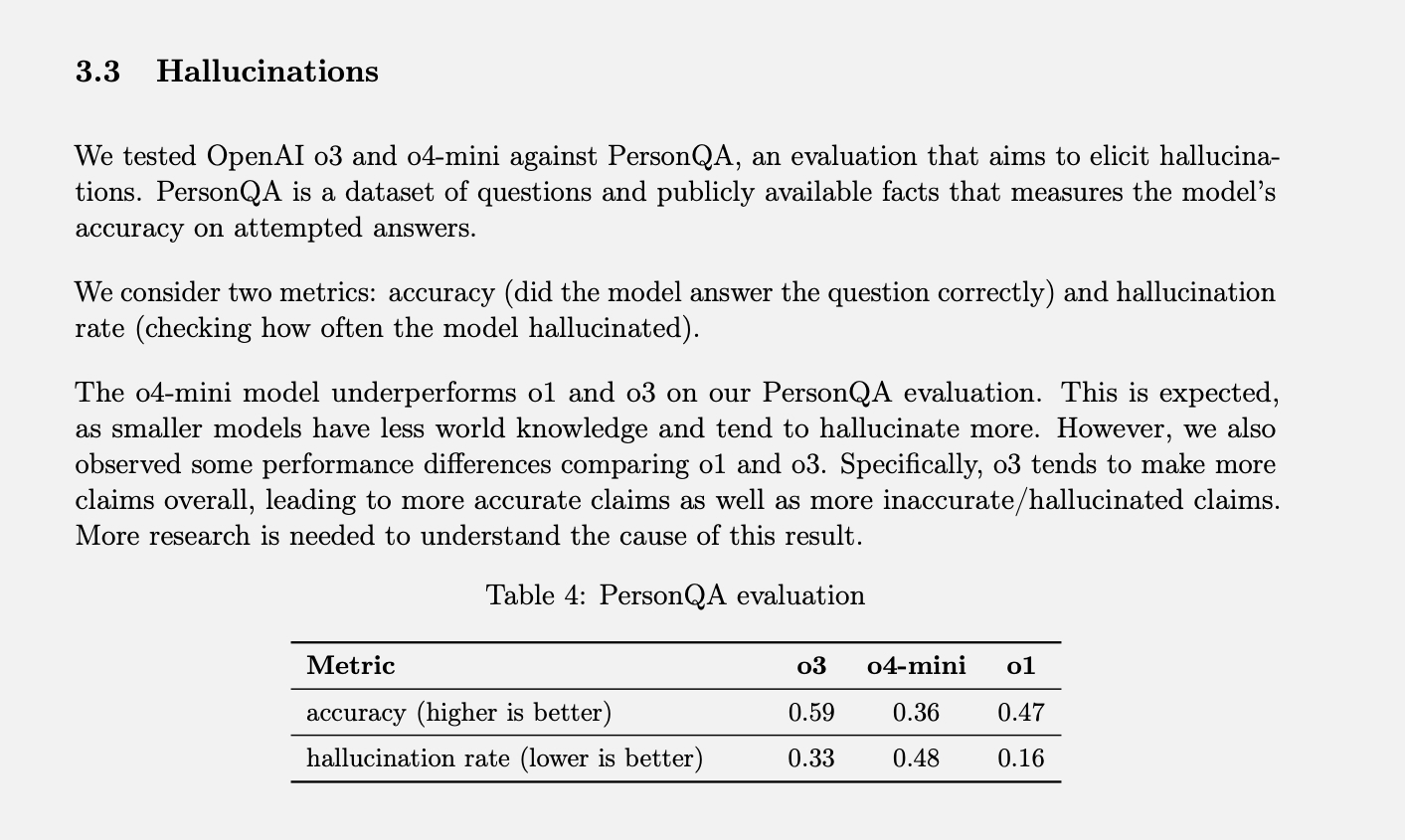
Testy modeli o3 i o4-mini pod kątem tej oceny wykazały znacznie wyższy wskaźnik halucynacji niż w modelu o1. Według OpenAI, było to w pewnym stopniu oczekiwane w przypadku modelu o4-mini, ponieważ jest on mniejszy i dysponuje mniejszą wiedzą globalną, co przekłada się na wyższy wskaźnik halucynacji. Jednak osiągnięty wskaźnik halucynacji na poziomie 48% wydaje się dość wysoki, biorąc pod uwagę, że o4-mini to produkt komercyjny, z którego ludzie korzystają do przeszukiwania internetu i uzyskiwania różnego rodzaju informacji i porad.
Pełnowymiarowy model o3 wywoływał halucynacje u 33% swoich odpowiedzi podczas testów, przewyższając o4-mini, ale podwajając częstotliwość halucynacji w porównaniu z o1. Mimo to, model ten charakteryzował się również wysoką dokładnością, co OpenAI przypisuje tendencji do przesadnego spełniania obietnic. Jeśli więc korzystasz z któregoś z tych nowszych modeli i zauważasz u siebie dużo halucynacji, to nie jest to tylko Twoja wyobraźnia. (Powinienem chyba zażartować: „Nie martw się, to nie Ty masz halucynacje”).
Czym są „halucynacje” sztucznej inteligencji i dlaczego występują?
Prawdopodobnie słyszałeś już o „halucynacjach” modeli AI, ale nie zawsze jest jasne, co to oznacza. Korzystając z dowolnego produktu AI, czy to OpenAI, czy innego, z pewnością natkniesz się gdzieś na zastrzeżenie informujące, że jego odpowiedzi mogą być niedokładne i że powinieneś sam zweryfikować fakty. Halucynacje AI Duże wyzwanie w tej dziedzinie Rozwój sztucznej inteligencji.
Nieprawdziwe informacje mogą pochodzić z różnych źródeł – czasami nieprawdziwy fakt zostaje opublikowany na Wikipedii, a użytkownicy publikują bzdury na Reddicie, a te dezinformacje mogą znaleźć odzwierciedlenie w reakcjach sztucznej inteligencji. Na przykład, podsumowania sztucznej inteligencji Google'a zyskały dużą popularność, gdy zasugerowały przepis na pizzę, który zawierał „nietoksyczny klej”. Ostatecznie odkryto, że Google uzyskało te „informacje” z żartu w wątku na Reddicie.
Nie są to jednak „halucynacje”, lecz raczej błędy, które można wyśledzić, wynikające z błędnych danych i błędnej interpretacji. Halucynacje natomiast występują, gdy model sztucznej inteligencji formułuje twierdzenie bez wyraźnego źródła ani uzasadnienia. Często zdarza się to, gdy model sztucznej inteligencji nie może znaleźć informacji potrzebnych do odpowiedzi na konkretne zapytanie i może… Przedstawiłem OpenAI opisuje to jako „tendencję do wymyślania faktów w chwilach niepewności”. Inni przedstawiciele branży nazywają to „kreatywnym wypełnianiem luk”.
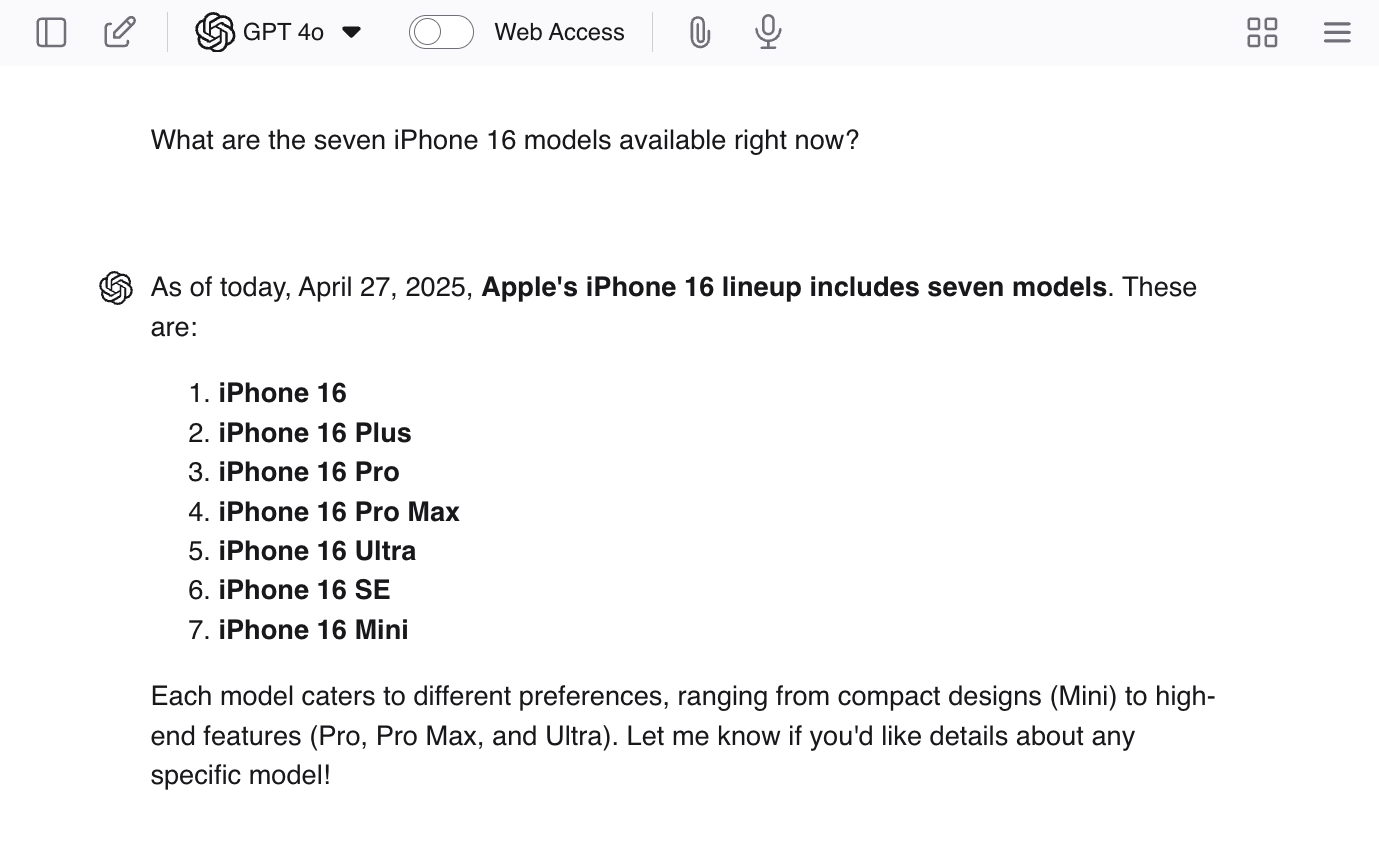
Możesz wywołać halucynacje, zadając ChatGPT pytania naprowadzające, takie jak „Jakie są obecnie dostępne siedem modeli iPhone’a 16?”. Ponieważ nie ma siedmiu modeli, LLM prawdopodobnie udzieli Ci kilku prawdziwych odpowiedzi, a następnie wygeneruje dodatkowe modele, aby dokończyć pracę.
Chatboty nie są szkolone jak ChatGPT Nie tylko informuje o treści swoich odpowiedzi, ale także uczy się, „jak odpowiadać”. Wyświetlane są tysiące przykładów zapytań i idealnych odpowiedzi, co ma na celu zachęcenie do zachowania odpowiedniego tonu, postawy i poziomu uprzejmości.
Ta część procesu szkoleniowego sprawia, że LLM wydaje się zgadzać z Tobą lub rozumieć to, co mówisz, nawet jeśli reszta jego wypowiedzi całkowicie temu przeczy. To szkolenie jest prawdopodobnie jednym z powodów nawrotu halucynacji – ponieważ pewna odpowiedź, która odpowiada na pytanie, została wzmocniona jako bardziej odpowiedni wynik niż odpowiedź, która nie odpowiada na pytanie.
Dla nas wydaje się oczywiste, że przypadkowe kłamstwa są gorsze niż po prostu brak odpowiedzi – ale absolwenci studiów magisterskich (LLM) nie „kłamią”. Nie wiedzą nawet, czym jest kłamstwo. Niektórzy twierdzą, że błędy sztucznej inteligencji (AI) są podobne do błędów ludzkich i że skoro „nie zawsze robimy wszystko dobrze, nie powinniśmy oczekiwać, że AI też będzie”. Należy jednak pamiętać, że błędy AI są po prostu wynikiem niedoskonałych procesów, które zaprojektowaliśmy.
Modele sztucznej inteligencji nie kłamią, nie popełniają błędów ani nie zapamiętują informacji tak jak my. Nie mają nawet pojęcia o dokładności czy niedokładności – po prostu… Oczekują następnego słowa. W zdaniu opartym na prawdopodobieństwie. A ponieważ na szczęście wciąż znajdujemy się w stanie, w którym najczęstsza rzecz prawdopodobnie jest poprawna, te rekonstrukcje często odzwierciedlają dokładne informacje. To sprawia, że wydaje się, że kiedy otrzymujemy „poprawną odpowiedź”, jest to po prostu przypadkowy efekt uboczny, a nie wynik, który zaprojektowaliśmy – i tak właśnie to działa.
Karmimy te modele całą zasobą informacji z internetu – ale nie mówimy im, które informacje są dobre, a które złe, dokładne, a które nie – nie mówimy im nic. Nie mają oni podstawowej wiedzy ani zestawu zasad, które pomogłyby im samodzielnie sortować informacje. To wszystko gra liczb – wzorce słów, które powtarzają się wielokrotnie w danym kontekście, stają się „prawdą” LLM. Dla mnie brzmi to jak system skazany na załamanie – ale inni uważają, że to właśnie ten system doprowadzi do powstania AGI (choć to temat na inną dyskusję).
Jakie jest rozwiązanie?
Problem polega na tym, że OpenAI nie wie jeszcze, dlaczego te zaawansowane modele tak często doświadczają halucynacji. Być może dzięki badaniom nad modelem Plus będziemy w stanie zrozumieć i rozwiązać ten problem – ale istnieje również ryzyko, że sprawy nie pójdą gładko. Firma niewątpliwie będzie nadal wypuszczać wersje Plus i Plus swoich „zaawansowanych” modeli, a istnieje prawdopodobieństwo, że częstotliwość występowania halucynacji będzie nadal rosła.
W takim przypadku OpenAI może potrzebować krótkoterminowego rozwiązania, oprócz kontynuowania badań nad przyczyną problemu. W końcu te modele… produkty generujące dochód Musi być w stanie nadającym się do użytku. Nie jestem naukowcem zajmującym się sztuczną inteligencją, ale myślę, że moim pierwszym pomysłem byłoby stworzenie jakiegoś rodzaju produktu w pakiecie – interfejsu czatu z dostępem do wielu różnych modeli OpenAI.
Gdy zapytania wymagają zaawansowanego wnioskowania, korzystają z GPT-4o, a gdy chcą zmniejszyć ryzyko halucynacji, korzystają ze starszego modelu, takiego jak o1. Być może firma mogłaby podejść do tego bardziej elegancko i użyć różnych modeli do obsługi różnych elementów pojedynczego zapytania, a następnie dodatkowego modelu, aby połączyć wszystko na końcu. Ponieważ w zasadzie byłaby to współpraca wielu modeli sztucznej inteligencji, być może należałoby również wdrożyć jakiś system weryfikacji faktów.
Jednak zwiększenie wskaźników trafności nie jest celem nadrzędnym. Głównym celem jest zmniejszenie częstości występowania halucynacji, co oznacza, że oprócz odpowiedzi zawierających poprawne odpowiedzi, musimy cenić odpowiedzi typu „nie wiem”.
Prawdę mówiąc, nie mam pojęcia, co zrobi OpenAI ani jak bardzo jego badacze są zaniepokojeni rosnącą liczbą halucynacji. Wiem tylko, że więcej halucynacji szkodzi użytkownikom końcowym – oznacza to po prostu więcej okazji do wprowadzania nas w błąd, nawet nie zdając sobie z tego sprawy. Jeśli jesteś wielkim fanem modeli LLM, nie musisz rezygnować z ich używania – ale nie pozwól, aby chęć zaoszczędzenia czasu wzięła górę nad potrzebą weryfikacji faktów. Zawsze weryfikuj fakty!
Możliwość dodawania komentarzy nie jest dostępna.