

Poprawa wykrywania w modelach transformatorowych poprzez dodanie szumu treningowego
Nowoczesne modele wizji transformatorowej dodają szum, aby poprawić wydajność wykrywania obiektów 2D i 3D. W tym artykule dowiemy się, jak działa ten mechanizm i omówimy jego wkład w poprawę dokładności modeli wykrywania obiektów, koncentrując się na wykorzystaniu technik takich jak odszumianie w procesie uczenia.

Modele transformatorowe do wczesnego widzenia
DETR – DEtection TRansformer (Carion, Massa i in., 2020), jedna z pierwszych architektur Transformer do wykrywania obiektów, wykorzystywała wyuczone zapytania kodera-dekodera do ekstrakcji informacji o wykryciu z tokenów obrazu. Zapytania te były inicjowane losowo, a architektura nie nakładała żadnych ograniczeń, które zmuszałyby je do uczenia się obiektów o charakterze kotwic. Chociaż osiągała podobne wyniki jak Faster-RCNN, jej wadą była powolna konwergencja – do jej wytrenowania potrzebnych było 500 epok (DN-DETR, Li i in., 2024). Nowsze architektury oparte na DETR wykorzystywały deformowalne łączenie, które umożliwiało zapytaniom koncentrowanie się tylko na określonych obszarach obrazu (Zhu i in., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), podczas gdy inne (Liu i in., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) wykorzystywały kotwice przestrzenne (generowane za pomocą k-średnich, podobnie jak sieci neuronowe oparte na kotwicach), które były kodowane w początkowych zapytaniach. Pominięte połączenia zmuszały blok dekodera Transformer do uczenia się pól jako wartości regresji z kotwic. Deformowalne warstwy uwagi wykorzystywały wstępnie zakodowane kotwice do próbkowania cech przestrzennych z obrazu i generowania tokenów uwagi. Podczas treningu model uczy się optymalnych kotwic do użycia. To podejście uczy model jawnego używania cech, takich jak rozmiar pola w swoich zapytaniach.
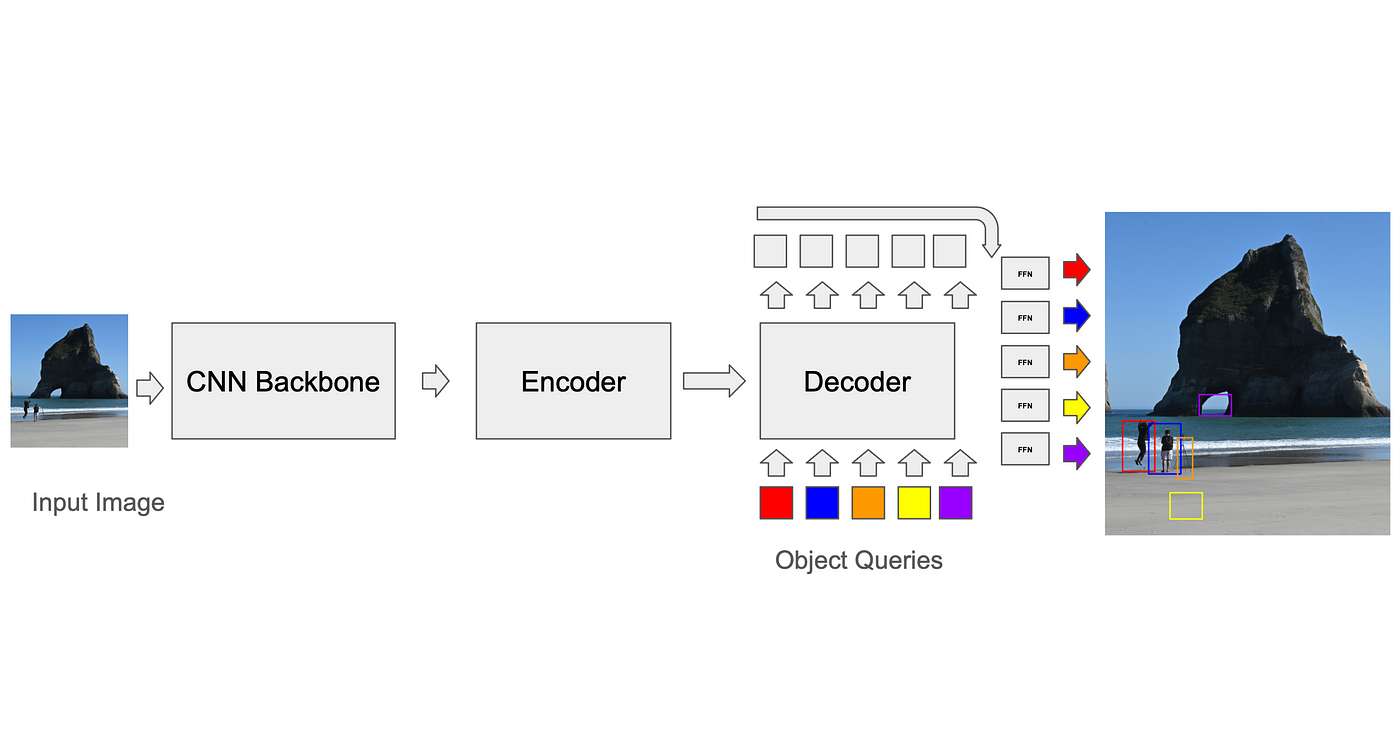
Dopasowywanie przewidywań do faktów bazowych: algorytm dopasowania binarnego
Aby obliczyć stratę, trenujący musi najpierw dopasować przewidywania modelu do pól prawdy podstawowej (GT). Podczas gdy sieci neuronowe oparte na kotwicach mają stosunkowo proste rozwiązania tego problemu (na przykład, każda kotwica może być dopasowana tylko do pól GT w swoim wokselu podczas treningu, a wnioskowanie, tłumienie niemaksymalne jest używane do usuwania nakładających się wykryć), standardem dla transformatorów, opracowanym przez DETR, jest użycie algorytmu dopasowania binarnego zwanego algorytmem węgierskim. W każdej iteracji algorytm znajduje najlepsze dopasowanie między przewidywaniem a prawdą podstawową (dopasowanie, które optymalizuje funkcję kosztu, taką jak średnia kwadratowa odległość między narożnikami pól, zsumowana po wszystkich polach). Strata między parami przewidywanie-prawda podstawowa jest następnie obliczana i może być propagowana wstecznie. Nadprzewidywania (przewidywania bez dopasowania GT) generują osobną stratę, która zachęca je do obniżenia wyniku ufności. Ten proces jest niezbędny do poprawy dokładności modelu i zmniejszenia liczby błędów.
problem
Złożoność czasowa algorytmu węgierskiego wynosi o(n³). Co ciekawe, niekoniecznie stanowi to wąskie gardło w jakości treningu: „The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective” (Fenoaltea i in., 2021) pokazuje, że algorytm jest niestabilny, co oznacza, że niewielka zmiana jego funkcji celu może prowadzić do dużej zmiany w wyniku dopasowania – prowadząc do niespójnych celów treningu zapytań. Praktyczne implikacje w treningu transformatorowym polegają na tym, że zapytania obiektowe mogą przeskakiwać między obiektami, co zajmuje dużo czasu, aby nauczyć się najlepszych cech dla zbieżności. Innymi słowy, niestabilność algorytmu prowadzi do oscylacji w procesie treningu, co wymaga dłuższego czasu, aby osiągnąć optymalne rezultaty.
DN-DETR (wykrywanie obiektów poprzez eliminację szumów)
Li i in. zaproponowali eleganckie rozwiązanie problemu niestabilnego dopasowania, które później przyjęto w wielu innych pracach, w tym DINO, Mask DINO, Group DETR i innych.
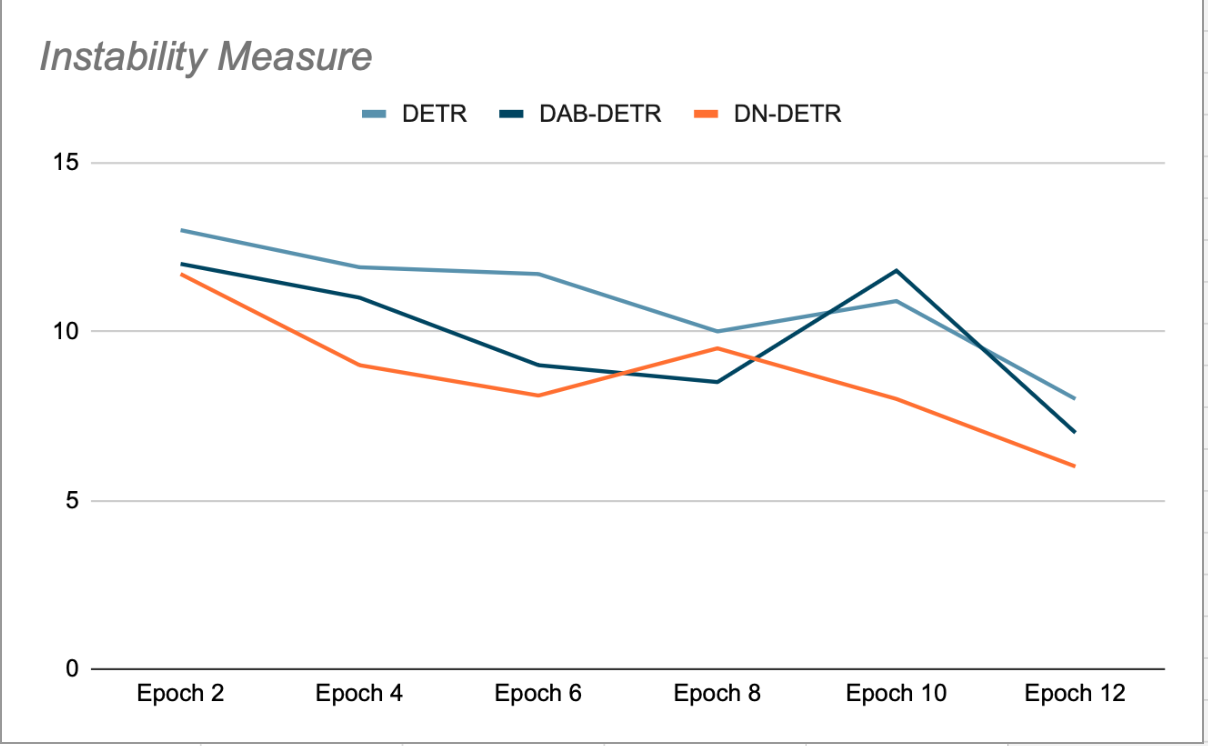
Główną ideą DN-DETR jest udoskonalenie szkolenia poprzez tworzenie Łatwe do nachylenia wyimaginowane punkty obrotuPomija proces dopasowywania. Odbywa się to podczas treningu poprzez dodanie niewielkiej ilości szumu do kafelków GT (rzeczywistego podłoża) i przekazanie tych zaszumionych kafelków jako punktów odniesienia dla zapytań dekodera. Zapytania DN są maskowane przed zapytaniami organicznymi i odwrotnie, aby uniknąć krzyżowania się uwagi, które mogłoby zakłócać trening. Wykrycia generowane przez te zapytania są już dopasowane do ich źródłowych kafelków GT i nie wymagają dwudzielnego dopasowania. Autorzy metody DN-DETR wykazali, że podczas faz walidacji pod koniec każdej epoki (gdzie usuwanie szumu jest wyłączone) poprawia to stabilność modelu w porównaniu z DETR i DAB-DETR, co oznacza, że zapytania Plus są spójne w dopasowywaniu do obiektu GT w kolejnych epokach (patrz rysunek 2).
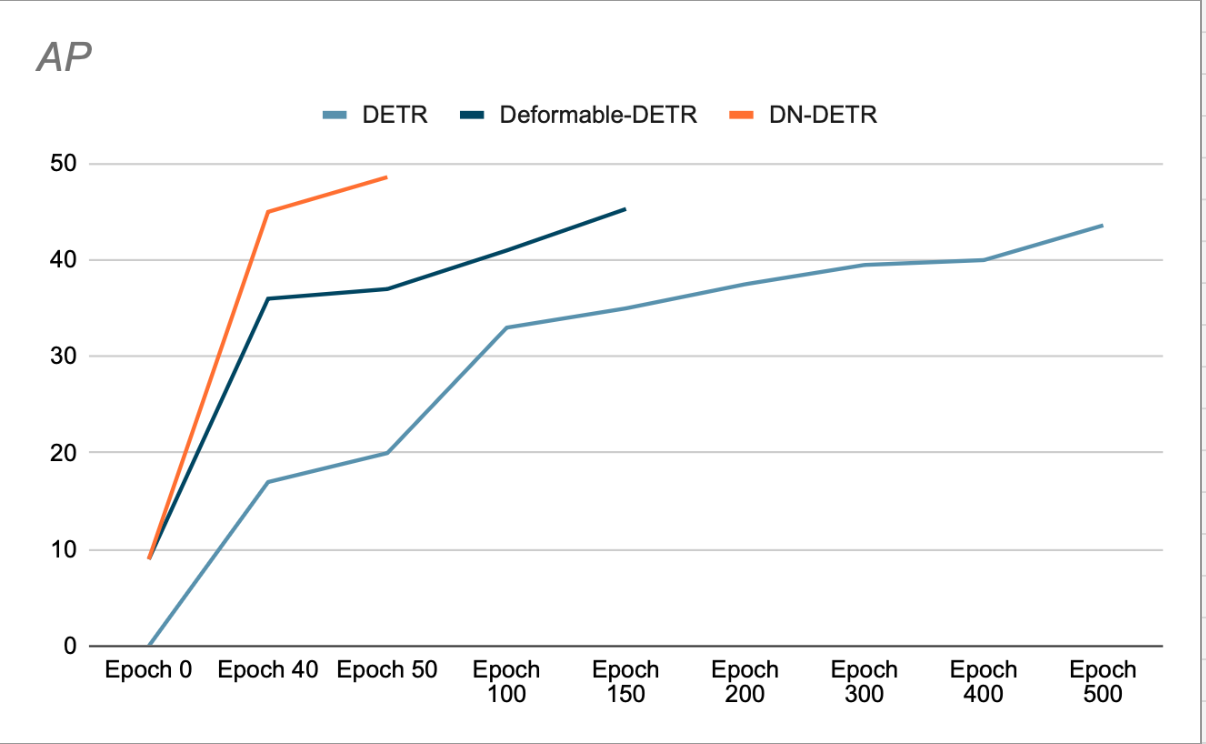
Autorzy wykazują, że wykorzystanie DN przyspiesza konwergencję i zapewnia lepsze wyniki detekcji (patrz rysunek 3). Ich badanie dotyczące usuwania danych pokazuje wzrost średniej dokładności AP (AP) o 1.9% w zestawie danych detekcji COCO, w porównaniu z poprzednim SOTA (DAB-DETR, AP 42.2%), przy użyciu ResNet-50 jako szkieletu sieci.
DINO i usuwanie szumów kontrastowych
DINO rozwinęło tę ideę, dodając uczenie kontrastywne do mechanizmu odszumiania: oprócz przykładu pozytywnego, DINO tworzy drugą, odszumioną wersję każdego GT, skonstruowaną matematycznie tak, aby była bardziej oddalona od GT niż przykład pozytywny (patrz rysunek 4). Ta wersja jest używana jako przykład negatywny do treningu: model uczy się akceptować wykrycie najbliższe prawdy i odrzucać wykrycie bardziej oddalone (ucząc się przewidywać klasę „brak obiektu”).
Ponadto DINO umożliwia wielokrotne klastrowanie na potrzeby kontrastowego odszumiania (CDN) – wiele zaszumionych punktów zaczepienia dla każdego obiektu GT – co pozwala na maksymalne wykorzystanie każdej iteracji treningu.
Autorzy DINO podali, że średnia precyzja (AP) wynosi 49% (według COCO val2017) przy użyciu CDN.
Nowoczesne modele temporalne wymagające śledzenia obiektów z klatki do klatki, takie jak Sparse4Dv3, korzystają z sieci CDN i dodają zestawy odszumiania czasowego, w których przechowywane są niektóre udane punkty zaczepienia nazw (wraz z poznanymi punktami zaczepienia innych niż nazwy) do wykorzystania w kolejnych klatkach, co zwiększa wydajność modelu w zakresie śledzenia obiektów.

Debata
Wydaje się, że odszumianie (DN) poprawia szybkość konwergencji i ostateczną wydajność detektorów transformatorów wizyjnych. Jednak analiza ewolucji różnych metod wymienionych powyżej nasuwa następujące pytania:
- DN ulepsza modele wykorzystujące kotwice z możliwością uczenia się. Ale czy kotwice z możliwością uczenia się są naprawdę ważne? I czy DN ulepszy również modele wykorzystujące kotwice nieuczące się?
- Głównym wkładem DN w uczenie jest zwiększenie stabilności procesu gradientu zstępującego poprzez pominięcie dopasowania dwudzielnego. Wydaje się jednak, że dopasowanie dwudzielne istnieje głównie dlatego, że standardem w pracy z transformatorami jest unikanie ograniczeń przestrzennych w zapytaniach. Zatem, jeśli ręcznie ograniczymy zapytania do określonych lokalizacji obrazów i zrezygnujemy z dopasowania dwudzielnego (lub użyjemy uproszczonej wersji dopasowania dwudzielnego, która jest uruchamiana osobno dla każdego fragmentu obrazu), czy DN nadal poprawi wyniki?
Nie udało mi się znaleźć żadnej pracy, która udzielałaby jasnych odpowiedzi na te pytania. Moja hipoteza jest taka, że model wykorzystujący nieuczone kotwice (pod warunkiem, że kotwice nie są zbyt rzadkie) i zapytania o ograniczeniach przestrzennych: 1. nie będzie wymagał algorytmu dopasowania binarnego oraz 2. nie skorzysta z treningu DN, ponieważ kotwice są już znane i nie ma korzyści z uczenia się regresji z innych efemerycznych kotwic.
Jeśli punkty zaczepienia są zamocowane na stałe, ale rozproszone, widzę, że użycie punktów zaczepienia efemerycznego ułatwia schodzenie i może zapewnić ciepły początek procesu szkolenia.
Metoda Anchor-DETR (Wand i in., 2021) porównuje rozkład przestrzenny uczących się i nieuczących się kotwic oraz wydajność poszczególnych modeli. Moim zdaniem, uczenie się nie dodaje znaczącej wartości do wydajności modelu. Warto zauważyć, że obie metody wykorzystują algorytm węgierski, więc nie jest jasne, czy można w nich zrezygnować z dopasowania binarnego, zachowując jednocześnie wydajność.
Należy pamiętać, że mogą istnieć powody, dla których należy unikać NMS w wnioskowaniu, co zachęca do stosowania algorytmu węgierskiego w szkoleniach.
Gdzie redukcja szumów może mieć naprawdę znaczenie? Moim zdaniem – w IdentyfikowalnośćW przypadku śledzenia model jest zasilany strumieniem wideo, a wymaganiem jest nie tylko wykrywanie wielu obiektów w kolejnych klatkach, ale także zachowanie unikalnej tożsamości każdego wykrytego obiektu. Modele transformatorów czasowych, czyli modele wykorzystujące sekwencyjny charakter strumienia wideo, nie przetwarzają poszczególnych klatek niezależnie. Zamiast tego przechowują bank danych, w którym przechowywane są poprzednie wykrycia. Podczas uczenia model śledzenia jest zachęcany do regresji od poprzedniego wykrycia obiektu (lub, dokładniej, punktu odniesienia powiązanego z poprzednim wykryciem obiektu), a nie po prostu od najbliższego punktu odniesienia. Ponieważ poprzednie wykrycie nie jest ograniczone przez jakąś stałą sieć punktów odniesienia, prawdopodobne jest, że elastyczność, jaką zapewnia DN, będzie korzystna. Bardzo chętnie przeczytałbym przyszłe prace, które poruszają te kwestie.
To wszystko o usuwaniu szumów i ich wpływie na transformację wizji! Jeśli spodobał Ci się mój artykuł, zapraszam do zapoznania się z innymi moimi artykułami na temat głębokiego uczenia się i uczenia maszynowego. widzenie komputerowe!
Możliwość dodawania komentarzy nie jest dostępna.