

Wypróbowałem nową funkcję Gemini do generowania obrazów i muszę przyznać, że jest ona absolutnie niesamowita.
Abstrakcyjny:
- Google wprowadził natywną funkcję generowania i edycji obrazów, wykorzystującą nową wersję beta Gemini 2.0 Flash.
- Funkcja ta jest już dostępna bezpłatnie w programie AI Studio i umożliwia generowanie i edycję serii skoordynowanych obrazów przy użyciu prostych poleceń tekstowych.
- Możesz usuwać i dodawać elementy, wstawiać tekst, kolorować obrazy, tworzyć historie wizualne i wiele więcej.
Termin „natywnie multimodalny” w kontekście sztucznej inteligencji pojawia się już od ponad roku, ale firmy do tej pory zwlekały z wykorzystaniem pełnego potencjału multimodalnego swoich modeli AI. Google w końcu wypuścił swój najnowszy model, „Gemini 2.0 Flash Experimental”, z Możliwość generowania i edytowania oryginalnych obrazówHej.
Pewnie zastanawiasz się, jaki jest sens generowania obrazów? Generowanie obrazów AI jest dostępne od jakiegoś czasu we wszystkich głównych chatbotach AI, takich jak ChatGPT. Kiedy generujemy obrazy AI w ChatGPT lub Gemini, kierujemy polecenie do specjalistycznego modelu propagacji, takiego jak Dall-E 3 lub Imagen 3. Modele te są trenowane na obrazach i zaprojektowane wyłącznie do generowania obrazów; stanowią rozszerzenie głównego modelu AI, a nie jego część.
Jednakże modele widzenia językowego, takie jak Gemini Natywnie multimodalny, co oznacza, że potrafi natywnie rozumieć, generować i modyfikować zarówno tekst, jak i obrazy. Do tej pory żadna firma technologiczna nie udostępniła tej funkcji użytkownikom. OpenAI zademonstrowało swoją natywną funkcję generowania obrazów z GPT-4o w 2024 roku, ale ponownie nigdy nie została ona wydana.
 Dzięki oryginalnej funkcji generowania obrazu otrzymasz: Lepsza spójność Modele multimodalne są trenowane na ogromnych zbiorach danych z różnych mediów. W rezultacie modele te lepiej rozumieją koncepcje i wykazują szerszą wiedzę o świecie.
Dzięki oryginalnej funkcji generowania obrazu otrzymasz: Lepsza spójność Modele multimodalne są trenowane na ogromnych zbiorach danych z różnych mediów. W rezultacie modele te lepiej rozumieją koncepcje i wykazują szerszą wiedzę o świecie.
Oprócz generowania obrazów, możesz je płynnie edytować za pomocą prostych poleceń tekstowych. Na przykład, możesz przesłać obraz i poprosić modelkę o dodanie okularów przeciwsłonecznych, wstawienie pogrubionego tekstu, usunięcie obiektów i wiele innych. W przeciwieństwie do modeli dyfuzyjnych, które regenerują cały obraz z każdym nowym poleceniem, natywne modele multimedialne zachowują spójność w wielu edycjach.
Twórz obrazy za pomocą demonstracji Gemini 2.0 Flash
Obecnie funkcja natywnego generowania obrazów nie jest dostępna dla zwykłych użytkowników. Wersja beta Gemini 2.0 Flash z natywnym generowaniem obrazów jest dostępna tylko na platformie Google AI Studio (ا) za darmo.
Po zapoznaniu się z modelem w AI Studio, zostanie on wkrótce udostępniony w Gemini do użytku dla wszystkich. Wypróbowałem jednak nowy model Gemini z funkcją generowania obrazu i było to bardzo ekscytujące doświadczenie.
Najpierw zacząłem od wizualnej demonstracji spójności zdolności Gemini do generowania obrazów. Poprosiłem Gemini o stworzenie wizualnej demonstracji, jak zrobić omlet, tworząc obraz dla każdego etapu procesu.
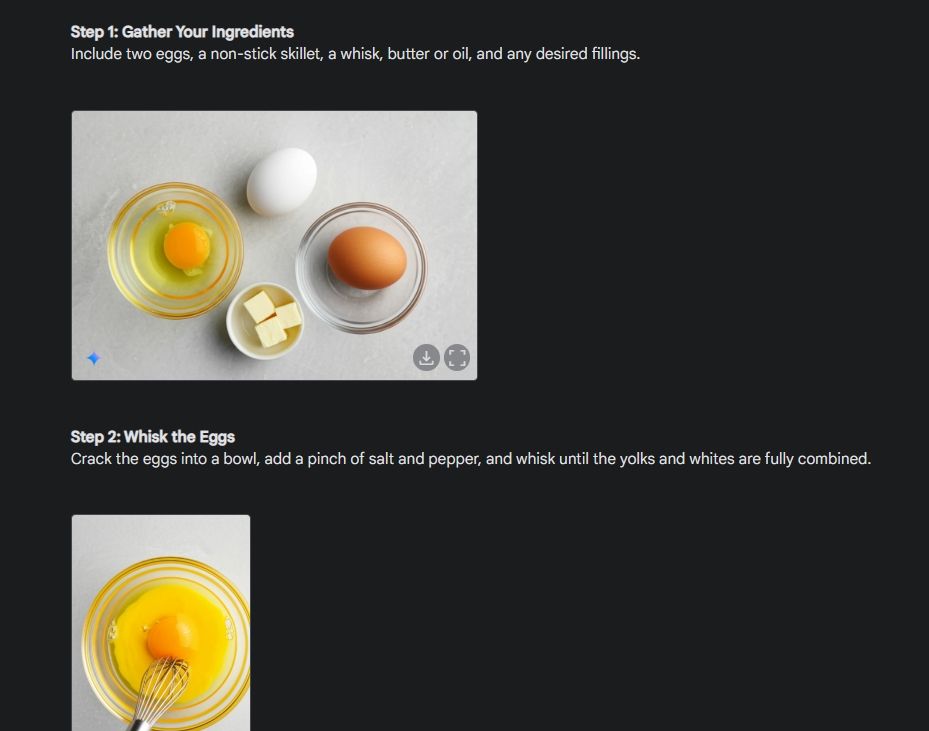
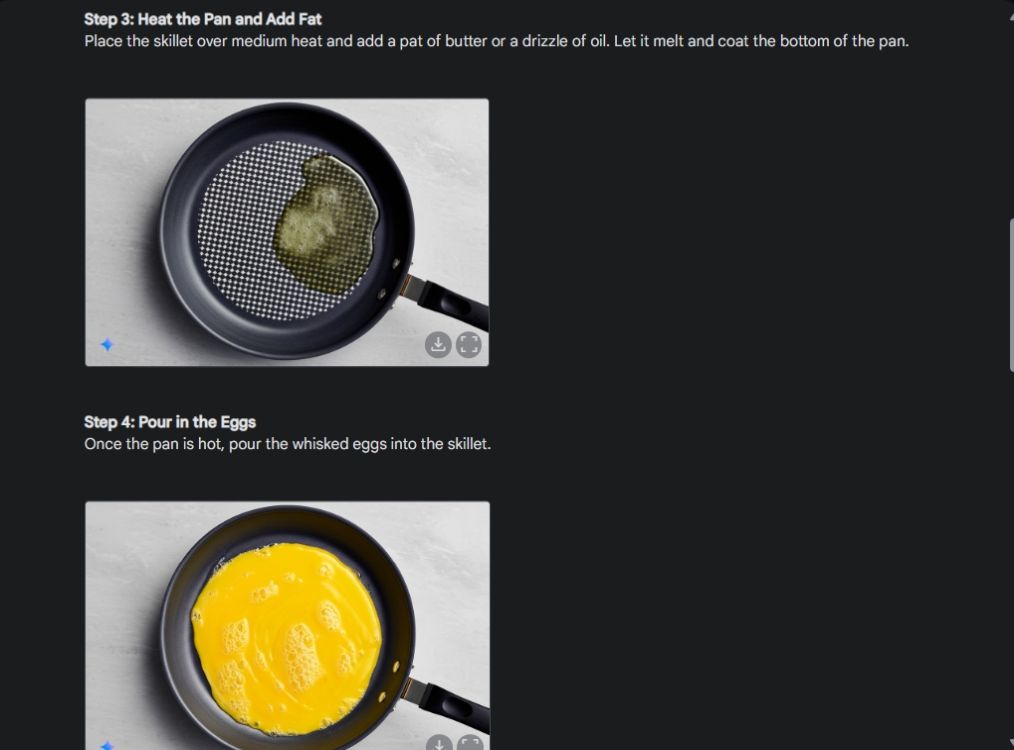

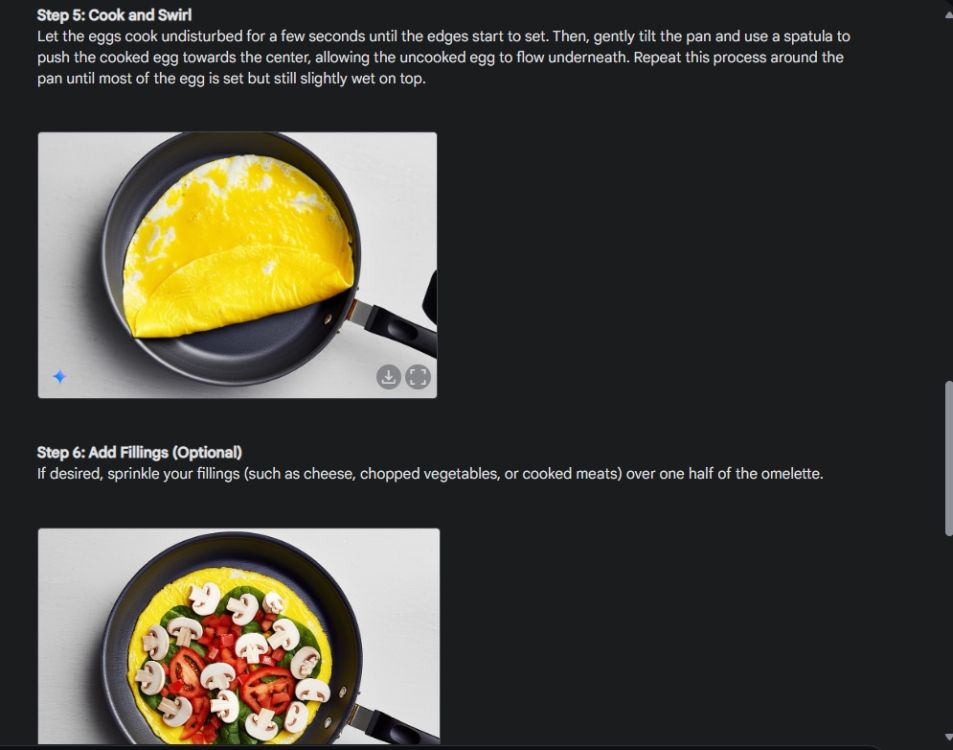
Jak widać, wyniki są bardzo spójne na wszystkich zdjęciach, bez błędów. Nawet miska jest taka sama na drugim zdjęciu. Możesz pobrać zdjęcia w rozdzielczości 1024 x 680. W ten sposób możesz stworzyć wizualny przewodnik po wszystkim, czego potrzebujesz.
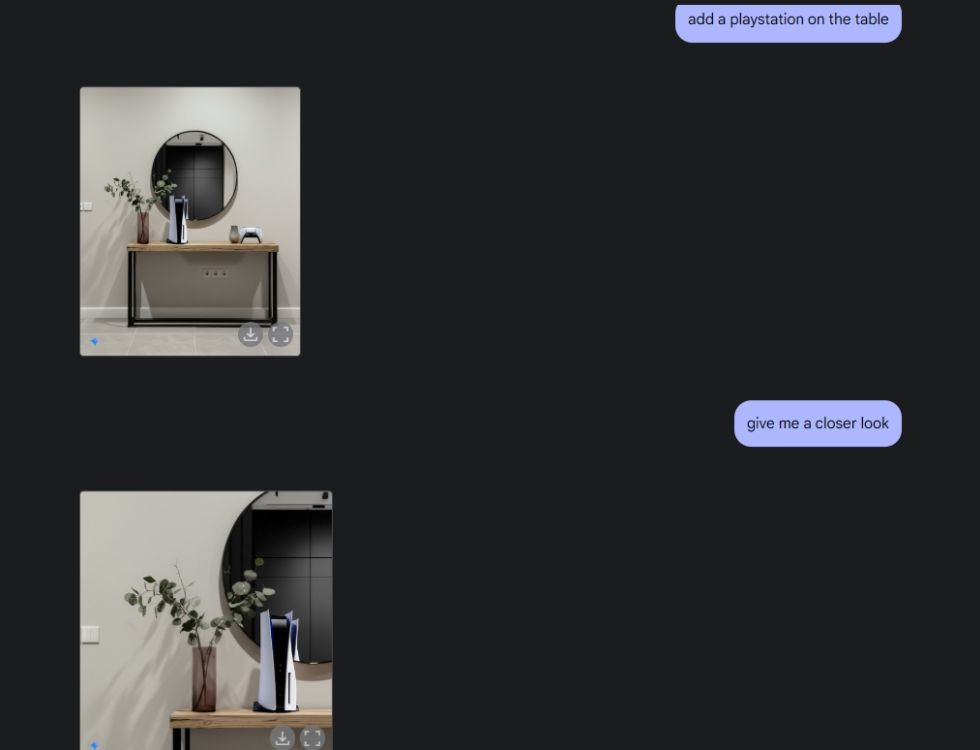
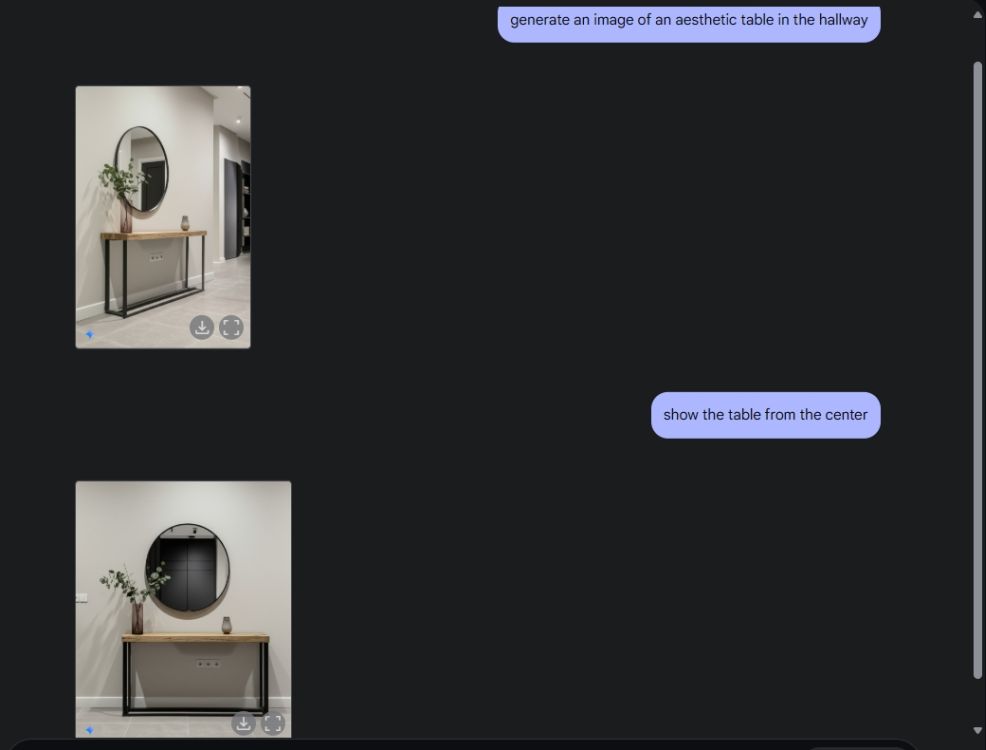
Następnie poprosiłem Gemini o stworzenie obrazu estetycznego stołu, a następnie obejrzenie go z centralnej kamery. Wykonał zadanie perfekcyjnie. Następnie poprosiłem Gemini o dodanie PlayStation do stołu i przyjrzenie się mu z bliska. I znów Gemini wykonał zadanie perfekcyjnie. Jak widać poniżej, model sztucznej inteligencji zawierał również odbicie PS5 w lustrze za nim.
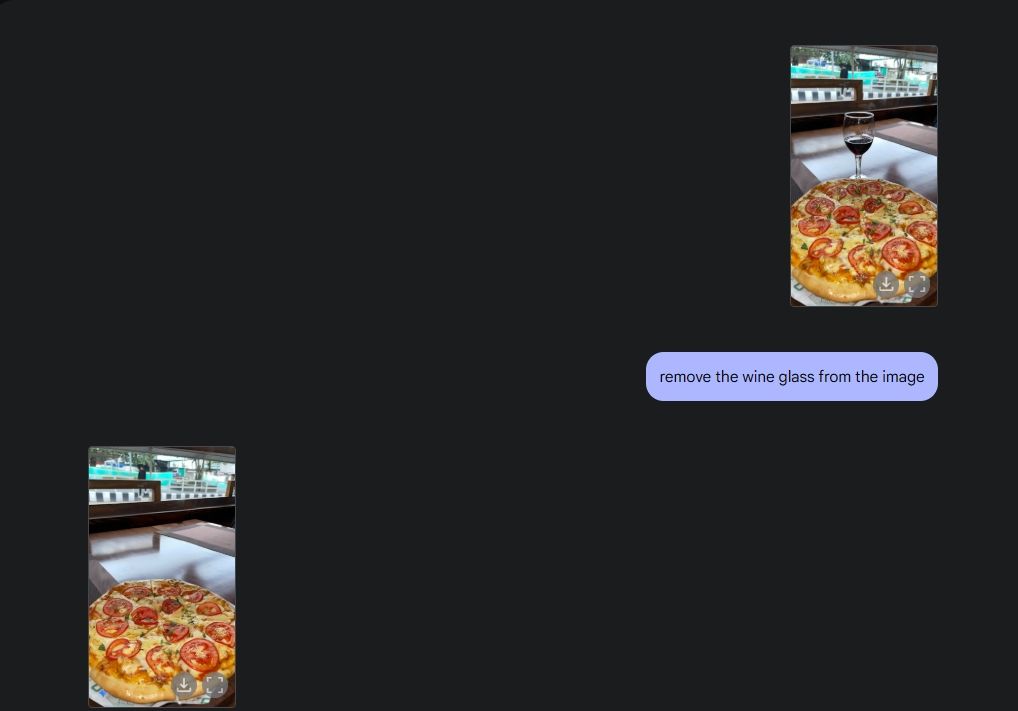
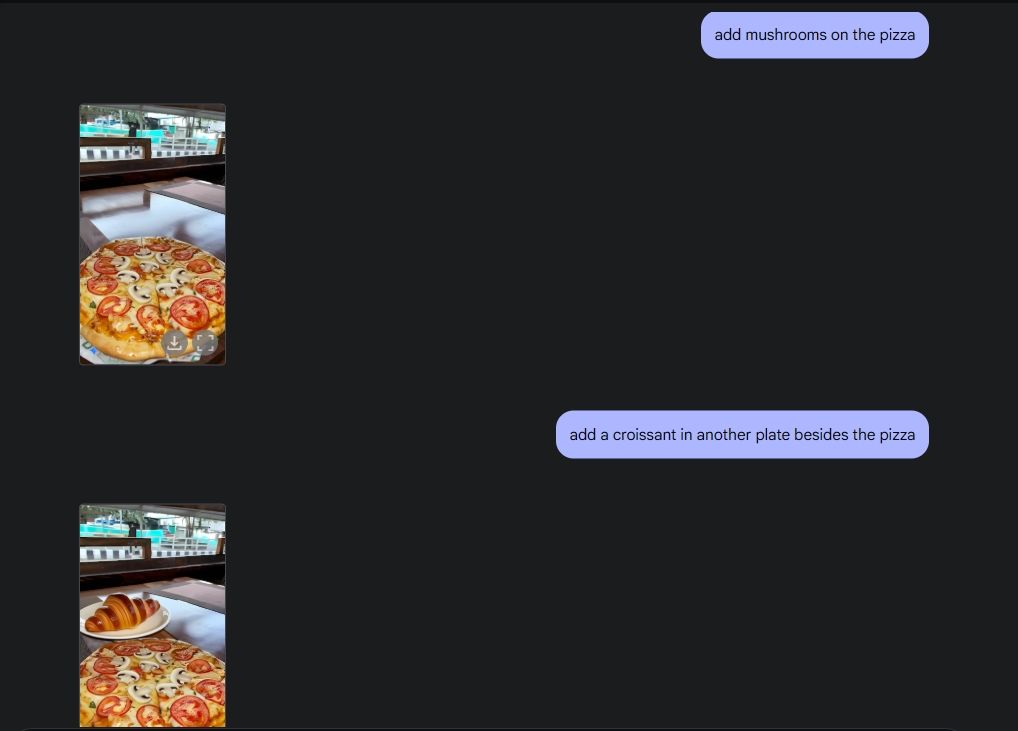
Aby zademonstrować oryginalną edycję zdjęć, wgrałem zdjęcie z mojej galerii i poprosiłem Gemini 2.0 o zdjęcie kieliszka do wina ze stołu. Następnie poprosiłem Gemini o dodanie pieczarek do pizzy i wykonałem świetną robotę. Następnie poprosiłem Gemini o dodanie croissanta i proszę bardzo, edycja zdjęć z AI w pełnej krasie, dzięki możliwościom multimedialnym Gemini.
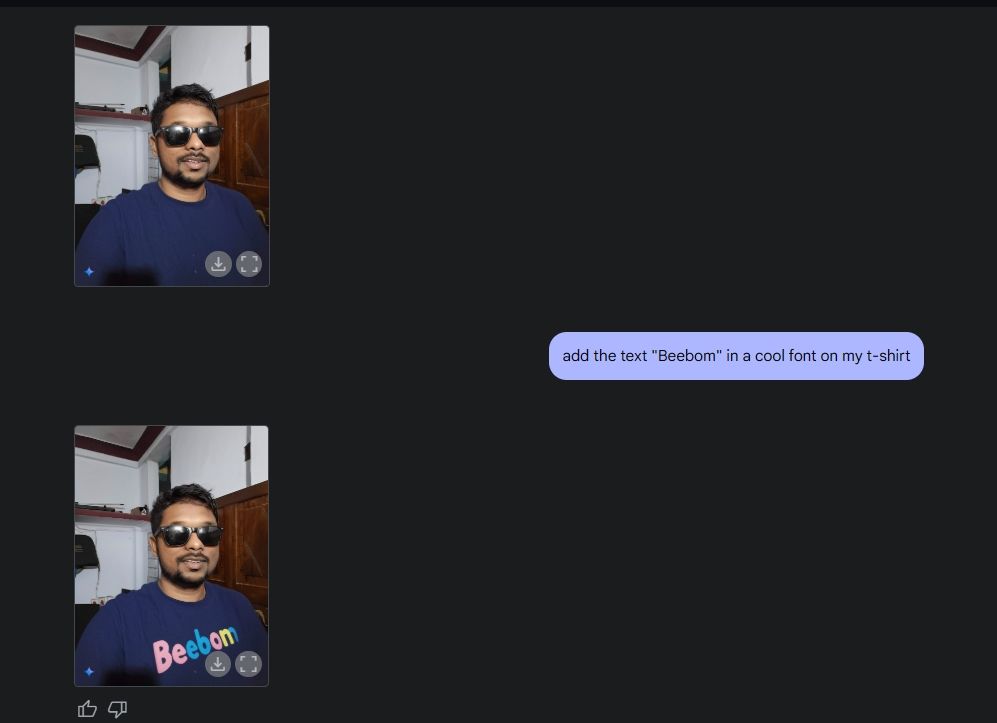
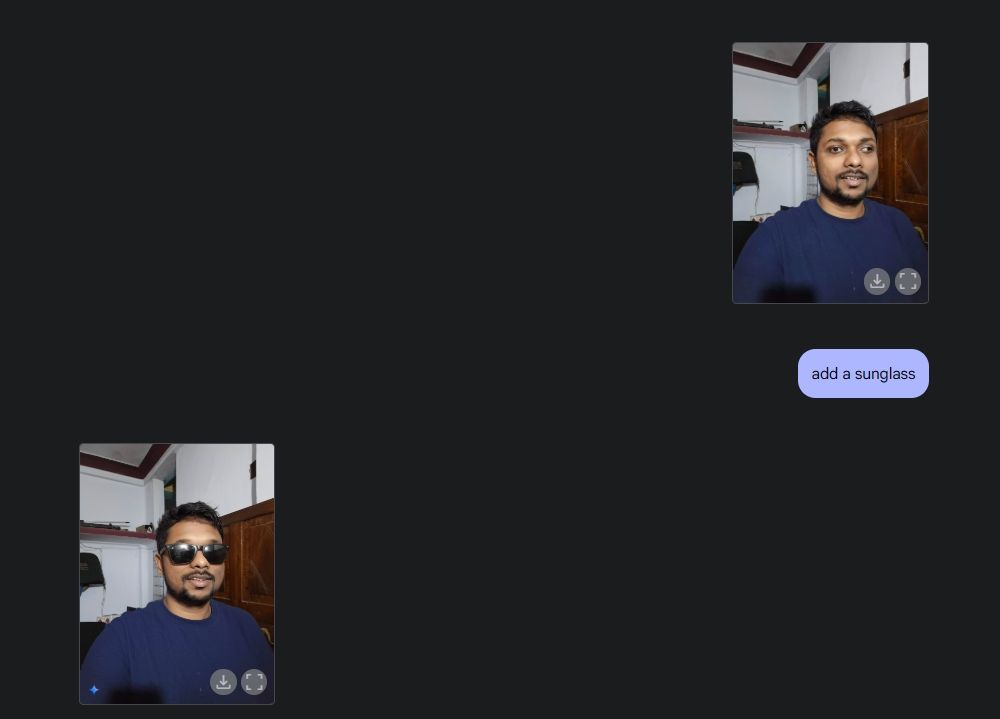
Następnie wgrałem swoje zdjęcie i poprosiłem Gemini o dodanie okularów przeciwsłonecznych i napisu „Beebom” na koszulce. Oba zadania zostały wykonane niezwykle dobrze.
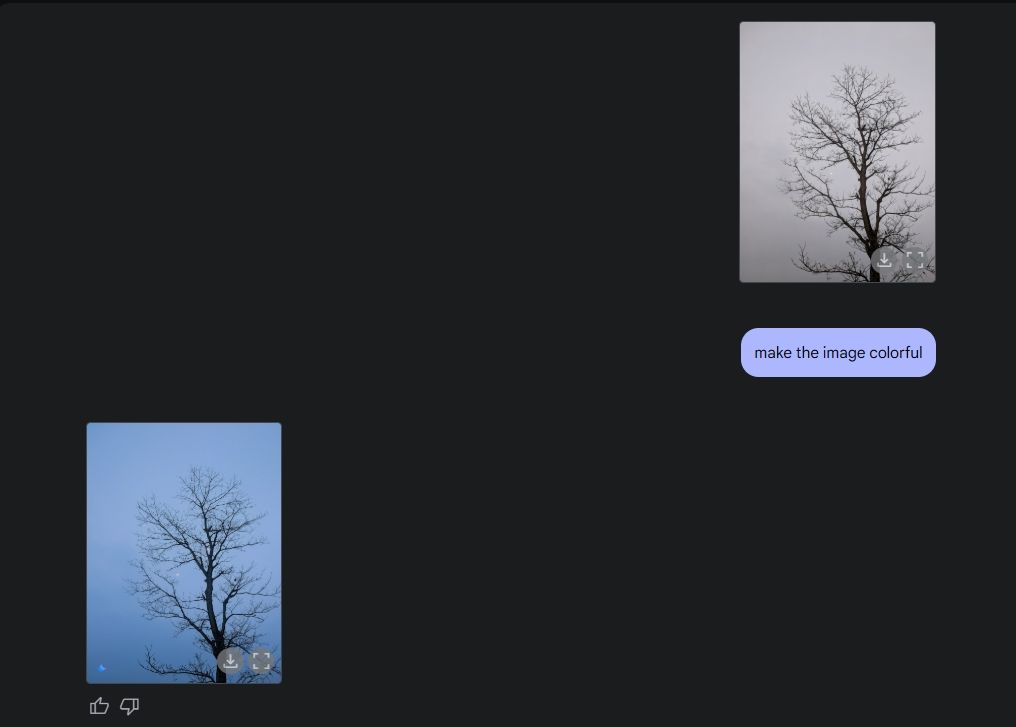
Na koniec poprosiłem Geminiego o pokolorowanie zdjęcia i on również wykonał świetną robotę. Zdjęcie wyglądało lepiej niż przedtem, bez żadnych dziwnych błędów, zniekształceń czy brakujących elementów.
Istnieje wiele zastosowań, z którymi możesz eksperymentować, korzystając z nowych funkcji multimedialnych Gemini. Google wykonało świetną robotę w zakresie natywnego tworzenia i edycji obrazów, a ja planuję korzystać z niego dokładniej w nadchodzących tygodniach, aby przetestować jego możliwości.
Wraz z wydaniem Veo 2 do tworzenia wideo i Imagen 3 do specjalistycznego generowania obrazów, Google najwyraźniej wyprzedziło OpenAI w wielu obszarach, nie tylko w generowaniu tekstu przez AI. Dlatego ciekawe będzie, co OpenAI zrobi, aby odzyskać przewagę nad ChatGPT.
Możliwość dodawania komentarzy nie jest dostępna.