

Jesteśmy świadkami boomu na modele sztucznej inteligencji (AI). Pojawia się jednak narastający problem: nazwy tych modeli stają się coraz bardziej złożone, tworząc labirynt akronimów i terminów technicznych, który dezorientuje nawet najbardziej zagorzałych użytkowników AI. Utrudnia to proces wyszukiwania i porównywania różnych modeli, wpływając negatywnie na zrozumienie ich zastosowań i możliwości.

Potrzebujemy prostszych etykiet dla modeli sztucznej inteligencji.
Pomimo innowacyjności każdego nowego modelu sztucznej inteligencji, ich skomplikowane nazwy stanowią istotną przeszkodę dla użytkowników próbujących je zrozumieć i rozróżnić. Ta złożoność nie tylko utrudnia przeciętnemu użytkownikowi dostęp do tych potężnych narzędzi, ale także tworzy istotną barierę w zrozumieniu i wykorzystaniu ich pełnego potencjału. Modele sztucznej inteligencji, uczenie maszynowe i przetwarzanie języka naturalnego to ważne terminy w tym kontekście.
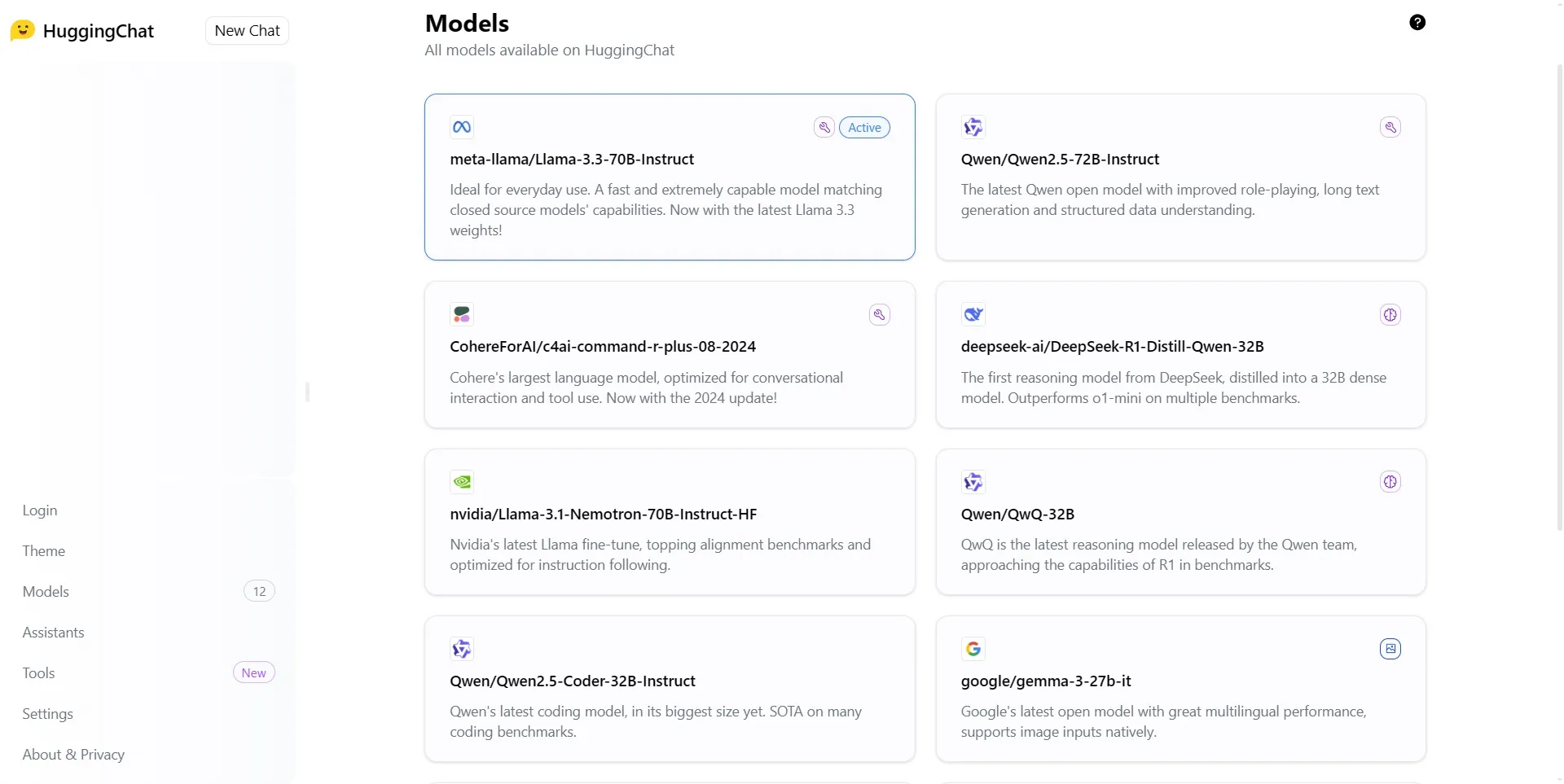
Na przykład, kiedy chiński gigant technologiczny Alibaba wypuścił swój model Qwen2.5-Coder-32B, kto tak naprawdę rozumiał, co on potrafi? Trzeba było przekopywać się przez specjalistyczny żargon, żeby się tego dowiedzieć.
Chociaż firmy zajmujące się sztuczną inteligencją często wybierają kreatywną nazwę dla produktu, taką jak Gemini, Mistral czy Lama, ostateczna nazwa modelu zawiera pewne atrybuty techniczne, takie jak numer wersji lub iteracji, architektura lub typ, liczba parametrów i inne specyficzne cechy. Na przykład nazwa Llama 2 70B-czat Ten model od Meta (Llama) to obszerny model językowy zawierający 70 miliardów (70B) parametrów, zaprojektowany specjalnie do celów konwersacyjnych (-chat).
Nazwa modelu sztucznej inteligencji stanowi w zasadzie skrót od jej najważniejszych cech, dzięki czemu badacze i użytkownicy techniczni mogą szybko zrozumieć jej naturę i cel — jednak dla przeciętnego człowieka jest ona często niezrozumiała.
Wyobraź sobie scenariusz, w którym użytkownik chce wybrać między najnowszymi modelami do konkretnego zadania. Ma do wyboru takie opcje, jak Gemini 2.0 Flash Thinking Experimental, DeepSeek R1 Distill Qwen 14B, Phi-3 Medium 14B i GPT-4o. Bez zagłębiania się w specyfikacje techniczne, rozróżnienie tych modeli staje się zniechęcającym zadaniem.
Ciąg nazw modeli, z których każda jest bardziej niezrozumiała od poprzedniej, podkreśla potrzebę fundamentalnej zmiany w sposobie nadawania nazw i prezentacji modeli AI. Idealnie, nazwa modelu AI powinna być prosta, jasna i łatwa do zapamiętania, odzwierciedlając jego cel i możliwości.
Wyobraź sobie, że samochody byłyby nazywane według specyfikacji silnika i typu zawieszenia, a nie według prostych, sugestywnych nazw, takich jak „Mustang” czy „Civic”. Obecne konwencje nazewnictwa modeli sztucznej inteligencji często przedkładają specyfikacje techniczne nad łatwość obsługi. Chociaż niektóre terminy są kluczowe dla badaczy, dla przeciętnego użytkownika są w dużej mierze bez znaczenia.
Branża musi przyjąć bardziej zorientowane na użytkownika podejście do nazewnictwa. Proste, intuicyjne i opisowe nazwy mogą znacząco poprawić doświadczenia użytkownika.
Łatwiejszy sposób odkrywania możliwości
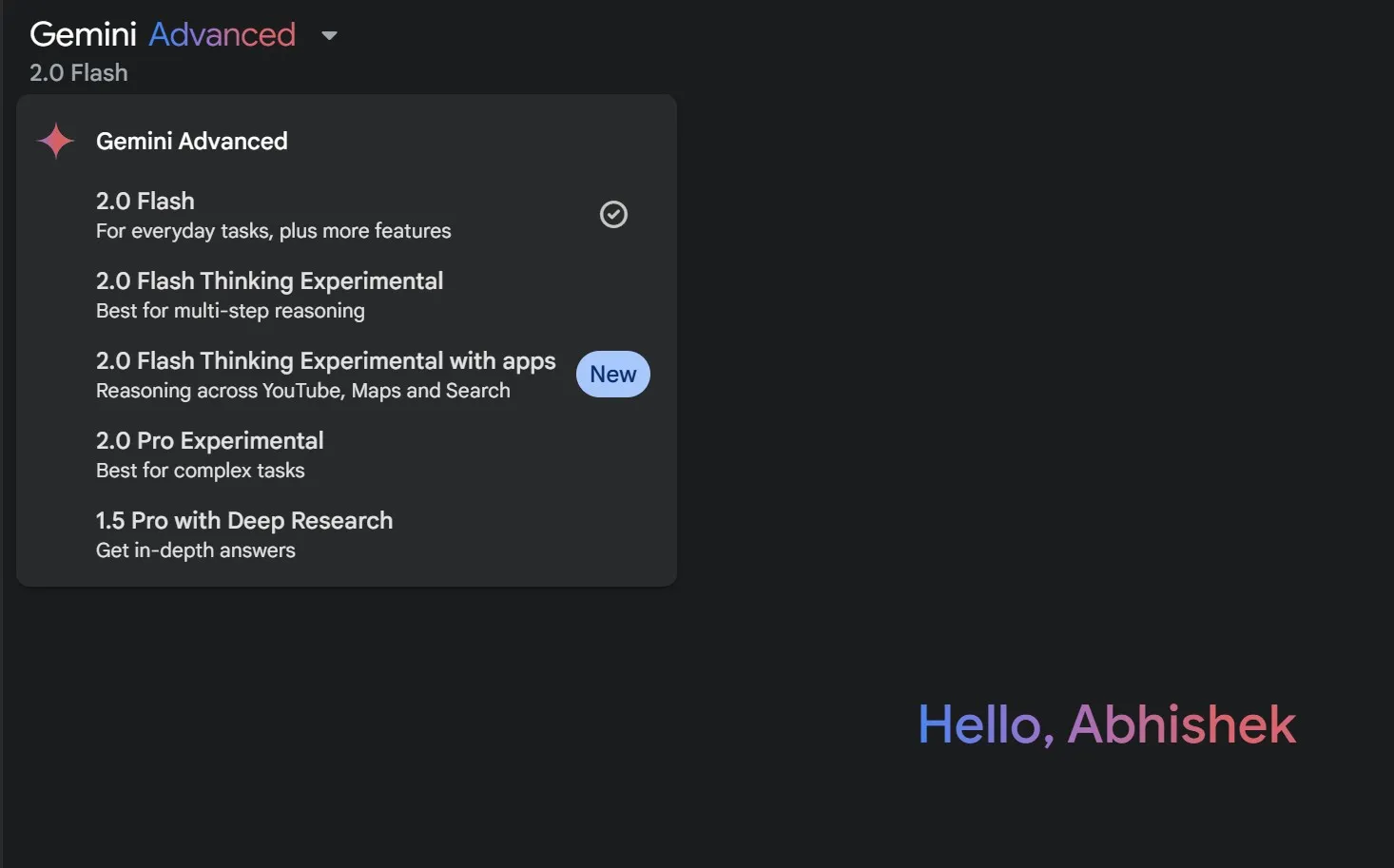
Oprócz mylących nazw, odkrycie możliwości konkretnego modelu AI stanowi kolejną istotną przeszkodę. Możliwości są często ukryte głęboko w dokumentacji technicznej. Sytuację pogarsza ogromna różnorodność modeli i wyspecjalizowanych funkcji. Sama nazwa może nie oddawać pełnego zakresu możliwości modelu AI. Zrozumienie możliwości modeli AI ma kluczowe znaczenie dla optymalnego wykorzystania tych zaawansowanych technologii.
Na szczęście narzędzia sztucznej inteligencji wykorzystujące te modele dodają krótki opis definiujący przypadek użycia lub jego możliwości – na przykład Google określa, że model Gemini 2.0 Flash Myślenie Wykorzystuje zaawansowane myślenie podczas przygotowywania 2.0 Pro Najlepiej sprawdza się w przypadku złożonych zadań. Nie jest to idealne rozwiązanie, ale istnieje pewna pomoc. To wyjaśnienie zawiera pewne wskazówki dla użytkowników, ale nadal jest ograniczone.
Zamiast opierać się na terminologii technicznej, nazwy modeli powinny odzwierciedlać ich główną funkcję lub możliwości. Jeśli konieczne jest użycie skrótów, należy je starannie dobrać, aby były łatwe do zapamiętania i wymówienia. Ponadto, jasne i zwięzłe numery wersji powinny wskazywać aktualizacje i udoskonalenia. Standardowe konwencje nazewnictwa mogą uprościć proces wyboru modelu.
Co więcej, modele AI można oznaczyć nazwami wyrażającymi ich główną funkcję lub unikalną cechę, takimi jak „chatbot”, „podsumowanie tekstu” lub „identyfikator obrazu”. Taka przejrzystość może zdemistyfikować technologię AI. Takie podejście uprości proces odkrywania, umożliwiając… Identyfikuj modele i narzędzia Najbardziej odpowiednia sztuczna inteligencja do Twoich zadań szybko Dzięki temu korzystanie z serwisu stanie się o wiele przyjemniejsze, ponieważ nie będzie trzeba przedzierać się przez labirynt niejasnych nazw i opisów.
Jednak większość modeli językowych ma zróżnicowane możliwości i może wykonywać więcej niż jedno zadanie. Dlatego to podejście może nie być idealne dla dużych, zaawansowanych modeli językowych. Duże modele językowe wykraczają poza proste klasyfikacje.

Możesz szybko stworzyć produktywny przepływ pracy, korzystając z różnych narzędzi AI.
Obecny stan nazewnictwa modeli AI może być mylący. Przejście na prostsze nazewnictwo i ulepszone metody wykrywania mogłyby znacząco poprawić komfort użytkowania i uczynić zaawansowane technologie bardziej dostępnymi. Zanim to nastąpi, pozostawanie na bieżąco, korzystanie z zasobów społeczności i eksperymentowanie z różnymi modelami może pomóc użytkownikom w poruszaniu się po złożonym świecie AI. Dzięki badaniom i eksperymentom użytkownicy mogą skutecznie wykorzystać potencjał AI.
Możliwość dodawania komentarzy nie jest dostępna.