

Sekrety telefonów, których potrzebują entuzjaści sztucznej inteligencji: maksymalne wykorzystanie Gemini i ChatGPT
Jednym z najbardziej zauważalnych – i szczerze mówiąc, najnudniejszych – trendów w branży smartfonów w ciągu ostatnich dwóch lat jest nieustanna dyskusja o doświadczeniach ze sztuczną inteligencją (AI). Firmy z branży krzemowej, w szczególności, często chwaliły się, jak ich najnowsze procesory mobilne umożliwią operacje AI na urządzeniach, takie jak tworzenie wideo.
Już tam dotarliśmy, choć nie do końca. Pośród całego szumu wokół sztuczek AI, które raz trafiają w gusta użytkowników smartfonów, dyskusja rzadko wychodzi poza efektowne prezentacje nowych procesorów i stale rozwijających się chatbotów.
Dopiero po tym, jak brak Gemini Nano w Google Pixel 8 wzbudził zdziwienie, opinia publiczna dowiedziała się o kluczowym znaczeniu pojemności pamięci RAM dla sztucznej inteligencji w urządzeniach mobilnych. Apple szybko wyjaśniło również, że Apple Intelligence będzie nadal oferować funkcje wyłącznie urządzeniom z co najmniej 8 GB pamięci RAM. Decyzja ta odzwierciedla znaczenie pamięci RAM dla efektywnego działania modeli sztucznej inteligencji.
Ale wizerunek „telefonu ze sztuczną inteligencją” to nie tylko kwestia pojemności pamięci. To, jak dobrze Twój telefon radzi sobie z zadaniami wspomaganymi przez sztuczną inteligencję, zależy również od niewidocznych ulepszeń pamięci RAM, oprócz pamięci masowej. I nie, nie mówię tu tylko o pojemności.
Innowacje w zakresie pamięci trafią do telefonów ze sztuczną inteligencją.

Digital Trends spotkał się z firmą Micron, światowym liderem w dziedzinie pamięci i rozwiązań pamięci masowej, aby przeanalizować rolę pamięci RAM i pamięci masowej w sztucznej inteligencji smartfonów. Postępy firmy Micron powinny znaleźć się w centrum uwagi podczas następnych zakupów telefonu z wyższej półki.
Najnowsze produkty firmy z Idaho obejmują pamięć G9 NAND Mobile UFS 4.1 oraz moduły pamięci RAM 1γ (1-gamma) LPDDR5X do flagowych smartfonów. Jak więc te rozwiązania pamięciowe, poza zwiększeniem pojemności, rozwijają sztuczną inteligencję w smartfonach?
Zacznijmy od rozwiązania pamięci masowej NAND UFS 4.1 zastosowanego w modelu G9. Najważniejszą obietnicą jest oszczędne zużycie energii, zmniejszone opóźnienia i duża przepustowość.Standard UFS 4.1 może osiągnąć szczytową prędkość sekwencyjnego odczytu i zapisu na poziomie 4100 MB/s, co stanowi wzrost o 15% w porównaniu z generacją UFS 4.0, a jednocześnie zmniejsza opóźnienia.
Kolejną istotną zaletą jest to, że przenośne pamięci masowej nowej generacji Micron oferują pojemność do 2 TB. Co więcej, Micron zdołał zmniejszyć ich rozmiar, co czyni je idealnym rozwiązaniem dla składanych i smukłych telefonów nowej generacji, takich jak Samsung Galaxy krawędzi S25.
Przechodząc do rozwoju pamięci RAM, Micron opracował moduły RAM 1γ LPDDR5X. Oferują one maksymalną prędkość 9200 MT/s, mogą pomieścić o 30% więcej tranzystorów dzięki mniejszym rozmiarom i zużywają o 20% mniej energii. Micron wprowadził już nieco wolniejsze rozwiązanie pamięci RAM 1β (1-beta), które można znaleźć w smartfonach z serii Samsung Galaxy S25.
Interakcja między pamięcią masową a sztuczną inteligencją
Ben Rivera, dyrektor ds. marketingu produktów w dziale rozwiązań mobilnych firmy Micron, wyjaśnił, że firma Micron wprowadziła cztery kluczowe udoskonalenia w swoich najnowszych rozwiązaniach pamięci masowej, aby zapewnić szybsze działanie sztucznej inteligencji na urządzeniach mobilnych. Udoskonalenia te obejmują strefowy system plików UFS, defragmentację danych, przypięty system WriteBooster oraz inteligentny system śledzenia opóźnień.
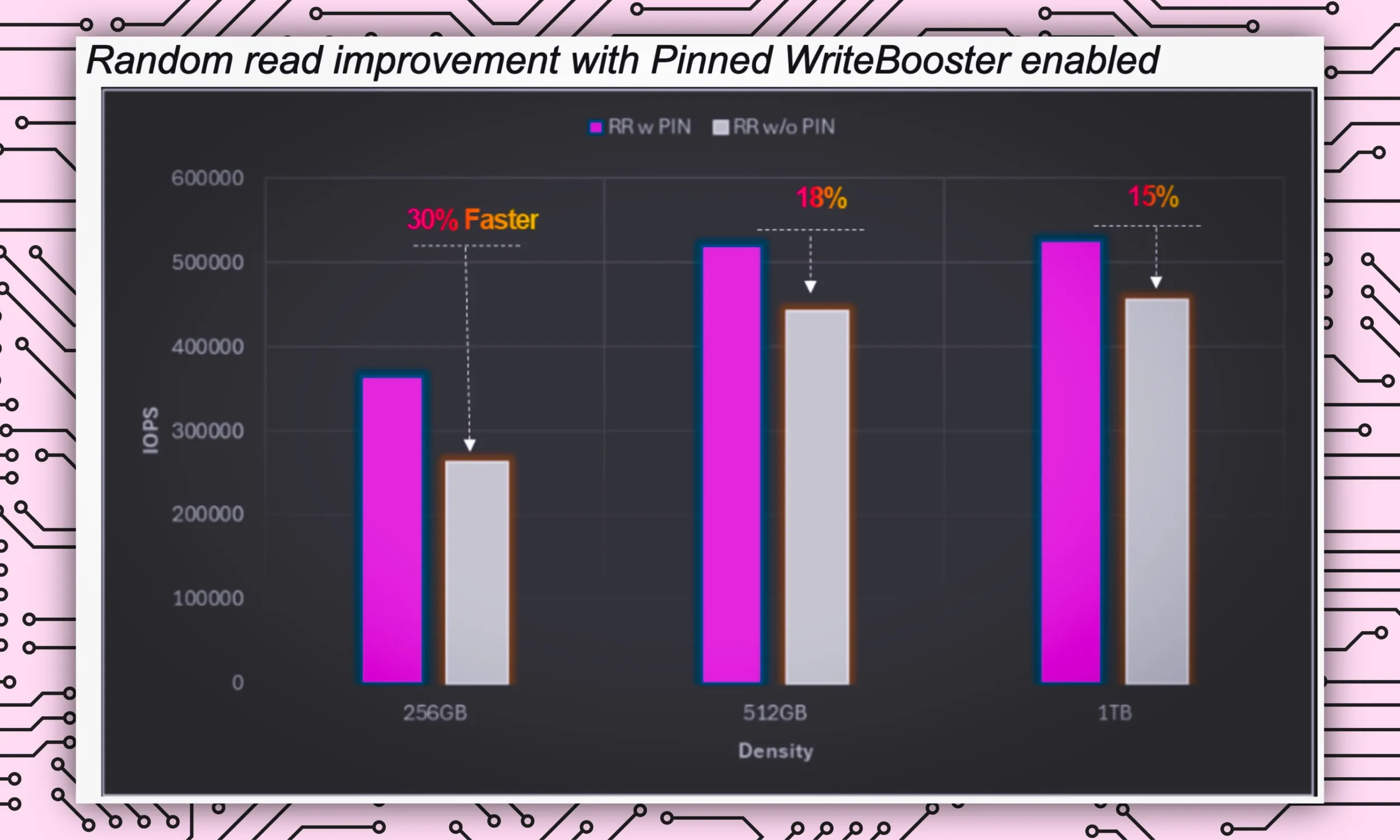
„Dzięki tej funkcji procesor lub host może zidentyfikować i wyizolować lub „przypiąć” najczęściej używane dane w smartfonie do obszaru urządzenia pamięci masowej zwanego buforem WriteBooster (podobnego do pamięci podręcznej), aby umożliwić szybki i natychmiastowy dostęp do nich” – wyjaśnia Rivera, opisując funkcję Pinned WriteBooster.
Każdy model sztucznej inteligencji (AI) – taki jak Google Gemini czy ChatGPT – który ma wykonywać zadania na urządzeniu, wymaga własnego zestawu plików instrukcji przechowywanych lokalnie na urządzeniu mobilnym. Na przykład: Apple Intelligence do 7 GB przestrzeni dyskowej We wszystkich swoich operacjach.
Aby wykonać zadanie, nie można delegować całego stosu AI do pamięci RAM, ponieważ będzie on potrzebował miejsca do obsługi innych krytycznych zadań, takich jak wykonywanie połączeń czy interakcja z innymi krytycznymi aplikacjami. Aby rozwiązać ograniczenia pamięci masowej Micron, stworzono mapę pamięci, która ładuje tylko wymagane wagi AI z pamięci masowej do pamięci RAM.
Gdy zasoby stają się ograniczone, potrzebna jest szybsza wymiana i odczyt danych. Dzięki temu zadania AI są wykonywane bez wpływu na szybkość innych kluczowych zadań. Dzięki Pinned WriteBooster wymiana danych przyspiesza się o 30%, zapewniając przetwarzanie zadań AI bez żadnych opóźnień.
Załóżmy, że potrzebujesz Gemini wyodrębni plik PDF do analizySzybka wymiana pamięci zapewnia szybkie przesłanie wymaganych wag sztucznej inteligencji z pamięci masowej do pamięci RAM.
Następnie mamy Data Defrag. Wyobraź sobie go jako organizer na biurko lub do szafy, który zapewnia uporządkowane pogrupowanie obiektów w różnych kategoriach i umieszczenie ich w odpowiednich przegródkach, aby łatwo je było znaleźć.
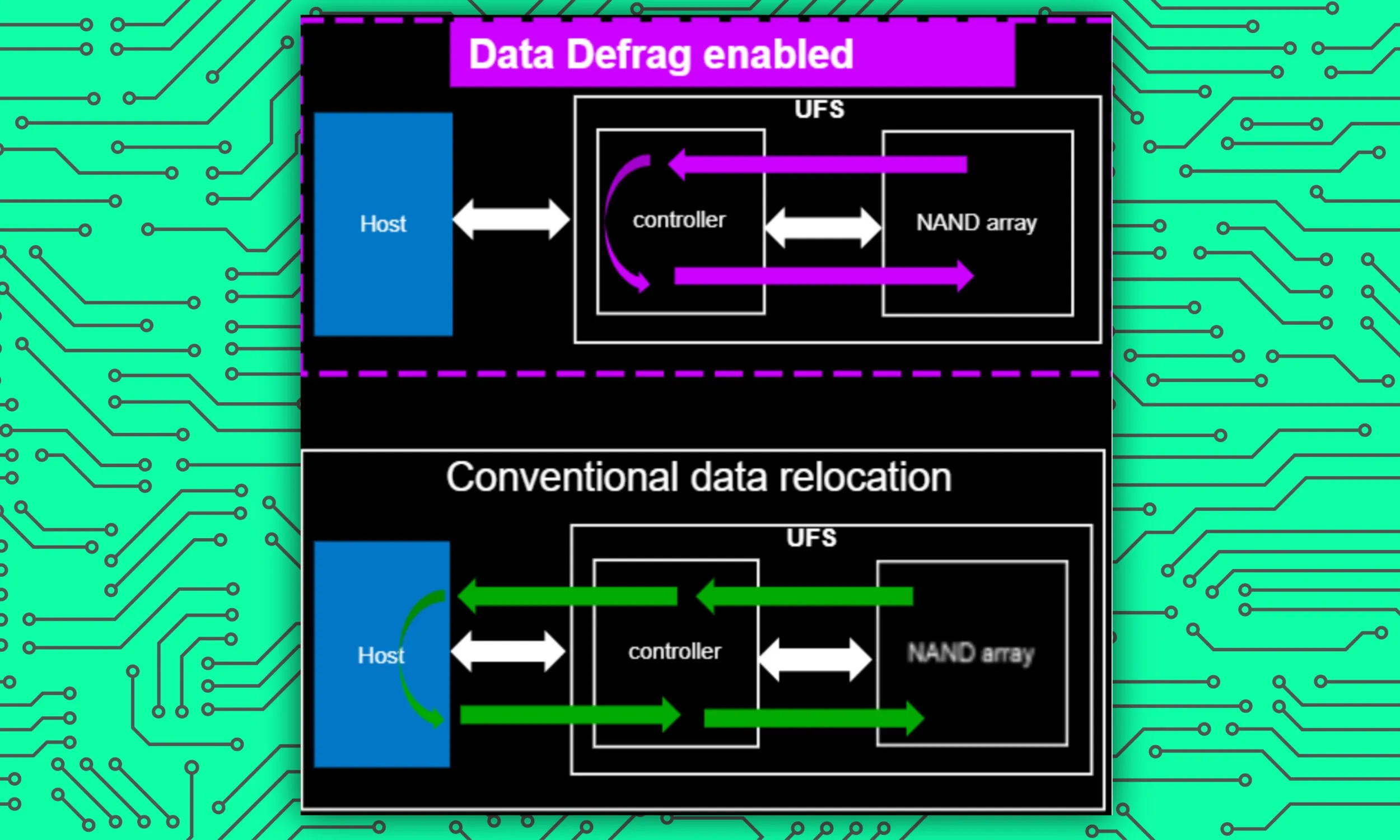
W kontekście smartfonów, mimo że duża ilość danych jest przechowywana przez długi okres użytkowania, zazwyczaj są one przechowywane w dość losowy sposób. W rezultacie, gdy system pokładowy potrzebuje dostępu do określonego typu pliku, znalezienie wszystkich staje się trudniejsze, co skutkuje wolniejszym działaniem.
Według Rivery, Data Defrag nie tylko pomaga w uporządkowanym przechowywaniu danych, ale także zmienia interakcję między urządzeniem pamięci masowej a jego kontrolerem. W ten sposób Zwiększa prędkość odczytu danych o niesamowite 60%, naturalnie przyspieszając wszystkie rodzaje interakcji użytkownika z urządzeniem, w tym zadania związane ze sztuczną inteligencją.
„Ta funkcja może przyspieszyć działanie funkcji AI, na przykład gdy generatywny model AI, np. ten używany do generowania obrazu z komunikatu tekstowego, jest wywoływany z pamięci masowej do pamięci masowej, co pozwala na szybszy odczyt danych z pamięci masowej” – powiedział przedstawiciel Micron w wywiadzie dla Digital Trends.
Intelligence Latency Tracker to kolejna funkcja, która przede wszystkim monitoruje opóźnienia i czynniki, które mogą spowalniać normalną prędkość działania telefonu. Następnie pomaga korygować błędy i poprawiać wydajność telefonu, aby zapewnić, że standardowe zadania, a także zadania AI, nie będą podlegać spadkom prędkości.
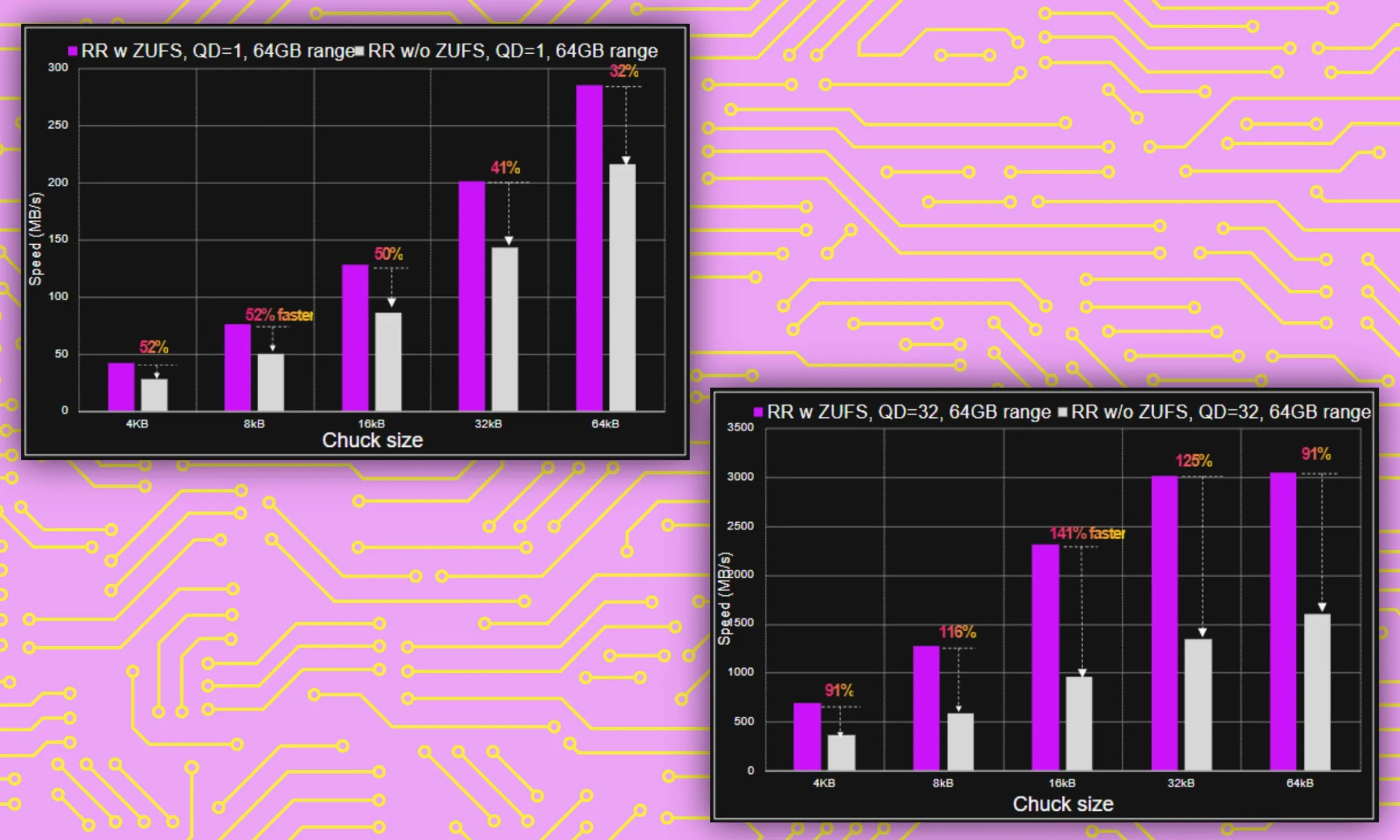
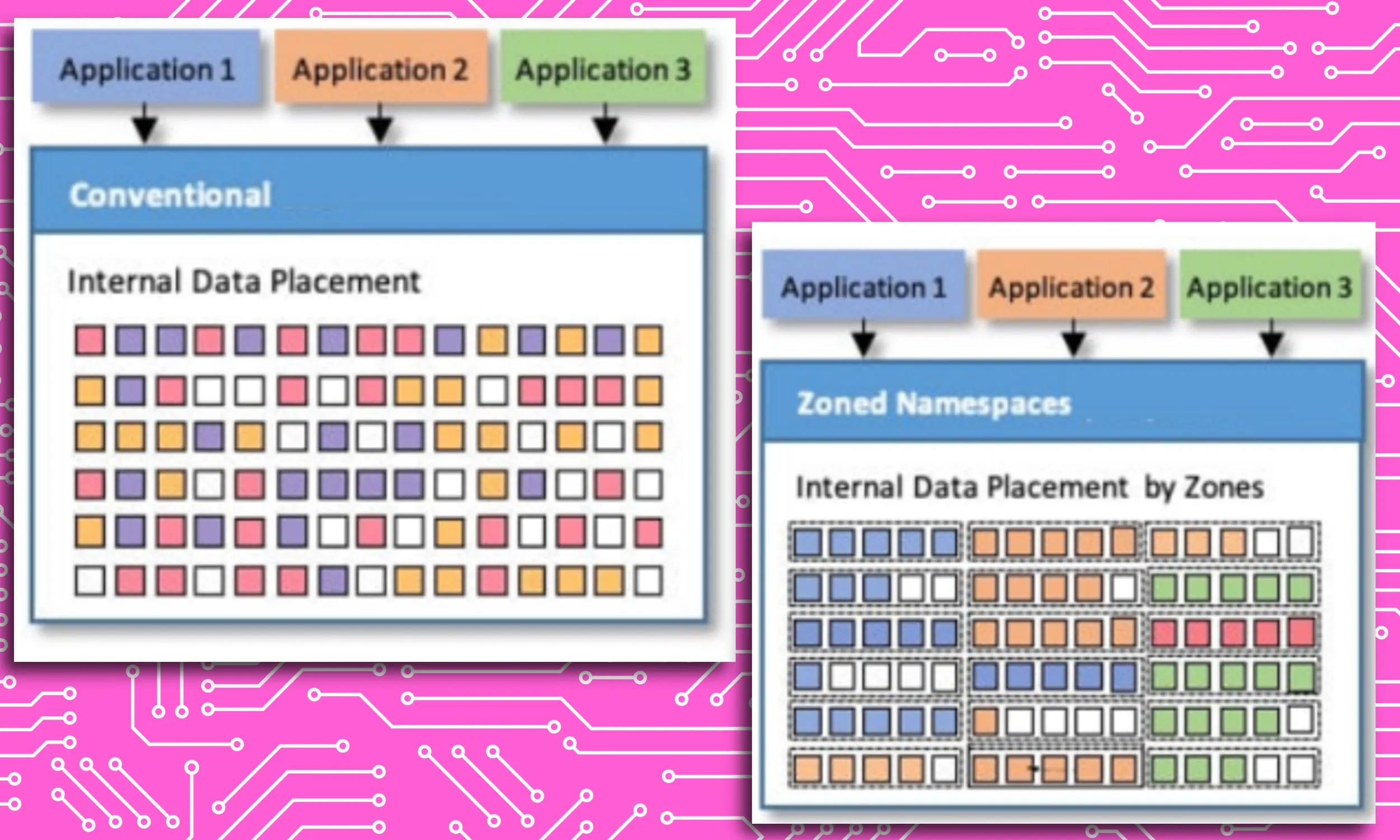
Ostatnim ulepszeniem pamięci masowej jest Strefowy System Plików UFS. System ten zapewnia uporządkowane przechowywanie danych o podobnych parametrach wejścia/wyjścia. Jest to kluczowe, ponieważ ułatwia systemowi lokalizowanie potrzebnych plików, zamiast tracić czas na przeszukiwanie wszystkich folderów i katalogów.
„Funkcja ZUFS firmy Micron pomaga organizować dane w taki sposób, że gdy system musi zlokalizować konkretne dane dla danego zadania, cały proces przebiega szybciej i sprawniej” – powiedział nam Rivera.
Przepełnienie pamięci RAM
W przypadku przepływów pracy związanych ze sztuczną inteligencją (AI) potrzebna jest określona ilość pamięci RAM. Im więcej RAM-u, tym lepiej. Podczas gdy Apple ustaliło limit bazowy na 8 GB dla swojego pakietu Apple Intelligence Suite, użytkownicy systemów Android przeszli na 12 GB jako bezpieczną wartość domyślną. Dlaczego?
„Doświadczenia związane ze sztuczną inteligencją wymagają również dużej ilości danych i energii” – wyjaśnia Rivera. „Dlatego, aby spełnić obietnice sztucznej inteligencji, pamięć i pamięć masowa muszą zapewniać niskie opóźnienia i wysoką wydajność przy maksymalnej efektywności energetycznej”.
Dzięki rozwiązaniu DRAM 1γ (1-gamma) LPDDR5X nowej generacji dla smartfonów, Micronowi udało się znacząco obniżyć napięcie robocze modułów pamięci. Dochodzi do tego niezwykle ważna kwestia wydajności lokalnej. Rivera twierdzi, że nowe moduły pamięci mogą pracować z prędkością do 9.6 gigabita na sekundę, zapewniając doskonałą wydajność sztucznej inteligencji.
Firma Micron twierdzi, że usprawnienia w jej procesie litografii w ekstremalnym ultrafiolecie (EUV) nie tylko umożliwiły osiągnięcie większych prędkości, ale także znaczny wzrost efektywności energetycznej o 20%.
Droga do bardziej spersonalizowanych doświadczeń związanych ze sztuczną inteligencją?
Rozwiązania pamięci RAM i pamięci masowej nowej generacji firmy Micron dla smartfonów mają na celu nie tylko poprawę wydajności sztucznej inteligencji (AI), ale także przyspieszenie codziennych zadań wykonywanych przez smartfony. Zastanawiałem się, czy ulepszona pamięć NAND Mobile UFS 4.1 i pamięć RAM 1γ (1-gamma) LPDDR5X w G9 przyspieszą również działanie procesorów AI pracujących w trybie offline.
Producenci smartfonów i laboratoria sztucznej inteligencji coraz częściej przechodzą na lokalne przetwarzanie AI. Oznacza to, że zamiast wysyłać zapytania do serwera w chmurze, gdzie proces jest przetwarzany, a następnie wyniki są przesyłane na telefon za pośrednictwem połączenia internetowego, cały proces jest wykonywany lokalnie na telefonie.

Od transkrypcji rozmów i notatek głosowych po przetwarzanie złożonych materiałów badawczych do plików PDF – wszystko dzieje się na Twoim telefonie, a żadne dane osobowe nigdy nie opuszczają Twojego urządzenia. To bezpieczniejsze i szybsze rozwiązanie, ale wymaga również znacznych zasobów systemowych. Jednym z tych niezbędnych wymagań jest szybszy i wydajniejszy moduł pamięci.
Czy rozwiązania nowej generacji firmy Micron mogą pomóc w lokalnym przetwarzaniu AI? Owszem. W rzeczywistości przyspieszą one również procesy wymagające łączności z chmurą, takie jak tworzenie wideo za pomocą modelu Veo firmy Google, które nadal wymaga wydajnych serwerów obliczeniowych.
„Natywna aplikacja AI działająca bezpośrednio na urządzeniu będzie generować największy ruch, ponieważ nie tylko odczytuje dane użytkownika z urządzenia pamięci masowej, ale także przeprowadza wnioskowanie AI na urządzeniu” – mówi Rivera. „W tym przypadku nasze funkcje pomogą zoptymalizować przepływ danych dla obu tych obszarów”.
Kiedy więc można spodziewać się, że telefony z najnowszymi rozwiązaniami Micron trafią na półki? Rivera twierdzi, że wszyscy czołowi producenci smartfonów wdrożą moduły pamięci RAM i pamięci masowej nowej generacji firmy Micron. Jeśli chodzi o termin wejścia na rynek, „główne modele, których premiera odbędzie się pod koniec 2025 lub na początku 2026 roku” powinny znaleźć się na celowniku zakupowym.
Możliwość dodawania komentarzy nie jest dostępna.